mirror of https://github.com/Mai-with-u/MaiBot.git
Merge branch 'debug' into Willing_cycles_and_better_response
commit
50db5e2ede
|
|
@ -0,0 +1,8 @@
|
||||||
|
name: Ruff
|
||||||
|
on: [ push, pull_request ]
|
||||||
|
jobs:
|
||||||
|
ruff:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v4
|
||||||
|
- uses: astral-sh/ruff-action@v3
|
||||||
|
|
@ -190,7 +190,6 @@ cython_debug/
|
||||||
|
|
||||||
# PyPI configuration file
|
# PyPI configuration file
|
||||||
.pypirc
|
.pypirc
|
||||||
.env
|
|
||||||
|
|
||||||
# jieba
|
# jieba
|
||||||
jieba.cache
|
jieba.cache
|
||||||
|
|
@ -199,4 +198,9 @@ jieba.cache
|
||||||
!.vscode/settings.json
|
!.vscode/settings.json
|
||||||
|
|
||||||
# direnv
|
# direnv
|
||||||
/.direnv
|
/.direnv
|
||||||
|
|
||||||
|
# JetBrains
|
||||||
|
.idea
|
||||||
|
*.iml
|
||||||
|
*.ipr
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
repos:
|
||||||
|
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||||
|
# Ruff version.
|
||||||
|
rev: v0.9.10
|
||||||
|
hooks:
|
||||||
|
# Run the linter.
|
||||||
|
- id: ruff
|
||||||
|
args: [ --fix ]
|
||||||
|
# Run the formatter.
|
||||||
|
- id: ruff-format
|
||||||
|
|
@ -61,6 +61,7 @@
|
||||||
|
|
||||||
- 📦 **Windows 一键傻瓜式部署**:请运行项目根目录中的 `run.bat`,部署完成后请参照后续配置指南进行配置
|
- 📦 **Windows 一键傻瓜式部署**:请运行项目根目录中的 `run.bat`,部署完成后请参照后续配置指南进行配置
|
||||||
|
|
||||||
|
- 📦 Linux 自动部署(实验) :请下载并运行项目根目录中的`run.sh`并按照提示安装,部署完成后请参照后续配置指南进行配置
|
||||||
|
|
||||||
- [📦 Windows 手动部署指南 ](docs/manual_deploy_windows.md)
|
- [📦 Windows 手动部署指南 ](docs/manual_deploy_windows.md)
|
||||||
|
|
||||||
|
|
|
||||||
99
bot.py
99
bot.py
|
|
@ -12,26 +12,11 @@ from loguru import logger
|
||||||
from nonebot.adapters.onebot.v11 import Adapter
|
from nonebot.adapters.onebot.v11 import Adapter
|
||||||
import platform
|
import platform
|
||||||
|
|
||||||
from src.common.database import Database
|
|
||||||
|
|
||||||
# 获取没有加载env时的环境变量
|
# 获取没有加载env时的环境变量
|
||||||
env_mask = {key: os.getenv(key) for key in os.environ}
|
env_mask = {key: os.getenv(key) for key in os.environ}
|
||||||
|
|
||||||
uvicorn_server = None
|
uvicorn_server = None
|
||||||
|
|
||||||
# 配置日志
|
|
||||||
log_path = os.path.join(os.getcwd(), "logs")
|
|
||||||
if not os.path.exists(log_path):
|
|
||||||
os.makedirs(log_path)
|
|
||||||
|
|
||||||
# 添加文件日志,启用rotation和retention
|
|
||||||
logger.add(
|
|
||||||
os.path.join(log_path, "maimbot_{time:YYYY-MM-DD}.log"),
|
|
||||||
rotation="00:00", # 每天0点创建新文件
|
|
||||||
retention="30 days", # 保留30天的日志
|
|
||||||
level="INFO",
|
|
||||||
encoding="utf-8"
|
|
||||||
)
|
|
||||||
|
|
||||||
def easter_egg():
|
def easter_egg():
|
||||||
# 彩蛋
|
# 彩蛋
|
||||||
|
|
@ -78,7 +63,7 @@ def init_env():
|
||||||
|
|
||||||
# 首先加载基础环境变量.env
|
# 首先加载基础环境变量.env
|
||||||
if os.path.exists(".env"):
|
if os.path.exists(".env"):
|
||||||
load_dotenv(".env",override=True)
|
load_dotenv(".env", override=True)
|
||||||
logger.success("成功加载基础环境变量配置")
|
logger.success("成功加载基础环境变量配置")
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -92,10 +77,7 @@ def load_env():
|
||||||
logger.success("加载开发环境变量配置")
|
logger.success("加载开发环境变量配置")
|
||||||
load_dotenv(".env.dev", override=True) # override=True 允许覆盖已存在的环境变量
|
load_dotenv(".env.dev", override=True) # override=True 允许覆盖已存在的环境变量
|
||||||
|
|
||||||
fn_map = {
|
fn_map = {"prod": prod, "dev": dev}
|
||||||
"prod": prod,
|
|
||||||
"dev": dev
|
|
||||||
}
|
|
||||||
|
|
||||||
env = os.getenv("ENVIRONMENT")
|
env = os.getenv("ENVIRONMENT")
|
||||||
logger.info(f"[load_env] 当前的 ENVIRONMENT 变量值:{env}")
|
logger.info(f"[load_env] 当前的 ENVIRONMENT 变量值:{env}")
|
||||||
|
|
@ -111,40 +93,45 @@ def load_env():
|
||||||
logger.error(f"ENVIRONMENT 配置错误,请检查 .env 文件中的 ENVIRONMENT 变量及对应 .env.{env} 是否存在")
|
logger.error(f"ENVIRONMENT 配置错误,请检查 .env 文件中的 ENVIRONMENT 变量及对应 .env.{env} 是否存在")
|
||||||
RuntimeError(f"ENVIRONMENT 配置错误,请检查 .env 文件中的 ENVIRONMENT 变量及对应 .env.{env} 是否存在")
|
RuntimeError(f"ENVIRONMENT 配置错误,请检查 .env 文件中的 ENVIRONMENT 变量及对应 .env.{env} 是否存在")
|
||||||
|
|
||||||
def init_database():
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
def load_logger():
|
def load_logger():
|
||||||
logger.remove() # 移除默认配置
|
logger.remove()
|
||||||
if os.getenv("ENVIRONMENT") == "dev":
|
|
||||||
logger.add(
|
|
||||||
sys.stderr,
|
|
||||||
format="<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> <fg #777777>|</> <level>{level: <7}</level> <fg "
|
|
||||||
"#777777>|</> <cyan>{name:.<8}</cyan>:<cyan>{function:.<8}</cyan>:<cyan>{line: >4}</cyan> <fg "
|
|
||||||
"#777777>-</> <level>{message}</level>",
|
|
||||||
colorize=True,
|
|
||||||
level=os.getenv("LOG_LEVEL", "DEBUG"), # 根据环境设置日志级别,默认为DEBUG
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
logger.add(
|
|
||||||
sys.stderr,
|
|
||||||
format="<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> <fg #777777>|</> <level>{level: <7}</level> <fg "
|
|
||||||
"#777777>|</> <cyan>{name:.<8}</cyan>:<cyan>{function:.<8}</cyan>:<cyan>{line: >4}</cyan> <fg "
|
|
||||||
"#777777>-</> <level>{message}</level>",
|
|
||||||
colorize=True,
|
|
||||||
level=os.getenv("LOG_LEVEL", "INFO"), # 根据环境设置日志级别,默认为INFO
|
|
||||||
filter=lambda record: "nonebot" not in record["name"]
|
|
||||||
)
|
|
||||||
|
|
||||||
|
# 配置日志基础路径
|
||||||
|
log_path = os.path.join(os.getcwd(), "logs")
|
||||||
|
if not os.path.exists(log_path):
|
||||||
|
os.makedirs(log_path)
|
||||||
|
|
||||||
|
current_env = os.getenv("ENVIRONMENT", "dev")
|
||||||
|
|
||||||
|
# 公共配置参数
|
||||||
|
log_level = os.getenv("LOG_LEVEL", "INFO" if current_env == "prod" else "DEBUG")
|
||||||
|
log_filter = lambda record: (
|
||||||
|
("nonebot" not in record["name"] or record["level"].no >= logger.level("ERROR").no)
|
||||||
|
if current_env == "prod"
|
||||||
|
else True
|
||||||
|
)
|
||||||
|
log_format = (
|
||||||
|
"<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> "
|
||||||
|
"<fg #777777>|</> <level>{level: <7}</level> "
|
||||||
|
"<fg #777777>|</> <cyan>{name:.<8}</cyan>:<cyan>{function:.<8}</cyan>:<cyan>{line: >4}</cyan> "
|
||||||
|
"<fg #777777>-</> <level>{message}</level>"
|
||||||
|
)
|
||||||
|
|
||||||
|
# 日志文件储存至/logs
|
||||||
|
logger.add(
|
||||||
|
os.path.join(log_path, "maimbot_{time:YYYY-MM-DD}.log"),
|
||||||
|
rotation="00:00",
|
||||||
|
retention="30 days",
|
||||||
|
format=log_format,
|
||||||
|
colorize=False,
|
||||||
|
level=log_level,
|
||||||
|
filter=log_filter,
|
||||||
|
encoding="utf-8",
|
||||||
|
)
|
||||||
|
|
||||||
|
# 终端输出
|
||||||
|
logger.add(sys.stderr, format=log_format, colorize=True, level=log_level, filter=log_filter)
|
||||||
|
|
||||||
|
|
||||||
def scan_provider(env_config: dict):
|
def scan_provider(env_config: dict):
|
||||||
|
|
@ -174,10 +161,7 @@ def scan_provider(env_config: dict):
|
||||||
# 检查每个 provider 是否同时存在 url 和 key
|
# 检查每个 provider 是否同时存在 url 和 key
|
||||||
for provider_name, config in provider.items():
|
for provider_name, config in provider.items():
|
||||||
if config["url"] is None or config["key"] is None:
|
if config["url"] is None or config["key"] is None:
|
||||||
logger.error(
|
logger.error(f"provider 内容:{config}\nenv_config 内容:{env_config}")
|
||||||
f"provider 内容:{config}\n"
|
|
||||||
f"env_config 内容:{env_config}"
|
|
||||||
)
|
|
||||||
raise ValueError(f"请检查 '{provider_name}' 提供商配置是否丢失 BASE_URL 或 KEY 环境变量")
|
raise ValueError(f"请检查 '{provider_name}' 提供商配置是否丢失 BASE_URL 或 KEY 环境变量")
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -206,7 +190,7 @@ async def uvicorn_main():
|
||||||
reload=os.getenv("ENVIRONMENT") == "dev",
|
reload=os.getenv("ENVIRONMENT") == "dev",
|
||||||
timeout_graceful_shutdown=5,
|
timeout_graceful_shutdown=5,
|
||||||
log_config=None,
|
log_config=None,
|
||||||
access_log=False
|
access_log=False,
|
||||||
)
|
)
|
||||||
server = uvicorn.Server(config)
|
server = uvicorn.Server(config)
|
||||||
uvicorn_server = server
|
uvicorn_server = server
|
||||||
|
|
@ -216,14 +200,13 @@ async def uvicorn_main():
|
||||||
def raw_main():
|
def raw_main():
|
||||||
# 利用 TZ 环境变量设定程序工作的时区
|
# 利用 TZ 环境变量设定程序工作的时区
|
||||||
# 仅保证行为一致,不依赖 localtime(),实际对生产环境几乎没有作用
|
# 仅保证行为一致,不依赖 localtime(),实际对生产环境几乎没有作用
|
||||||
if platform.system().lower() != 'windows':
|
if platform.system().lower() != "windows":
|
||||||
time.tzset()
|
time.tzset()
|
||||||
|
|
||||||
easter_egg()
|
easter_egg()
|
||||||
init_config()
|
init_config()
|
||||||
init_env()
|
init_env()
|
||||||
load_env()
|
load_env()
|
||||||
init_database() # 加载完成环境后初始化database
|
|
||||||
load_logger()
|
load_logger()
|
||||||
|
|
||||||
env_config = {key: os.getenv(key) for key in os.environ}
|
env_config = {key: os.getenv(key) for key in os.environ}
|
||||||
|
|
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 20 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 36 KiB |
|
|
@ -0,0 +1 @@
|
||||||
|
gource gource.log --user-image-dir docs/avatars/ --default-user-image docs/avatars/default.png
|
||||||
|
|
@ -121,6 +121,7 @@ sudo nano /etc/systemd/system/maimbot.service
|
||||||
输入以下内容:
|
输入以下内容:
|
||||||
|
|
||||||
`<maimbot_directory>`:你的maimbot目录
|
`<maimbot_directory>`:你的maimbot目录
|
||||||
|
|
||||||
`<venv_directory>`:你的venv环境(就是上文创建环境后,执行的代码`source maimbot/bin/activate`中source后面的路径的绝对路径)
|
`<venv_directory>`:你的venv环境(就是上文创建环境后,执行的代码`source maimbot/bin/activate`中source后面的路径的绝对路径)
|
||||||
|
|
||||||
```ini
|
```ini
|
||||||
|
|
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 107 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 208 KiB |
|
|
@ -0,0 +1,67 @@
|
||||||
|
# 群晖 NAS 部署指南
|
||||||
|
|
||||||
|
**笔者使用的是 DSM 7.2.2,其他 DSM 版本的操作可能不完全一样**
|
||||||
|
**需要使用 Container Manager,群晖的部分部分入门级 NAS 可能不支持**
|
||||||
|
|
||||||
|
## 部署步骤
|
||||||
|
|
||||||
|
### 创建配置文件目录
|
||||||
|
|
||||||
|
打开 `DSM ➡️ 控制面板 ➡️ 共享文件夹`,点击 `新增` ,创建一个共享文件夹
|
||||||
|
只需要设置名称,其他设置均保持默认即可。如果你已经有 docker 专用的共享文件夹了,就跳过这一步
|
||||||
|
|
||||||
|
打开 `DSM ➡️ FileStation`, 在共享文件夹中创建一个 `MaiMBot` 文件夹
|
||||||
|
|
||||||
|
### 准备配置文件
|
||||||
|
|
||||||
|
docker-compose.yml: https://github.com/SengokuCola/MaiMBot/blob/main/docker-compose.yml
|
||||||
|
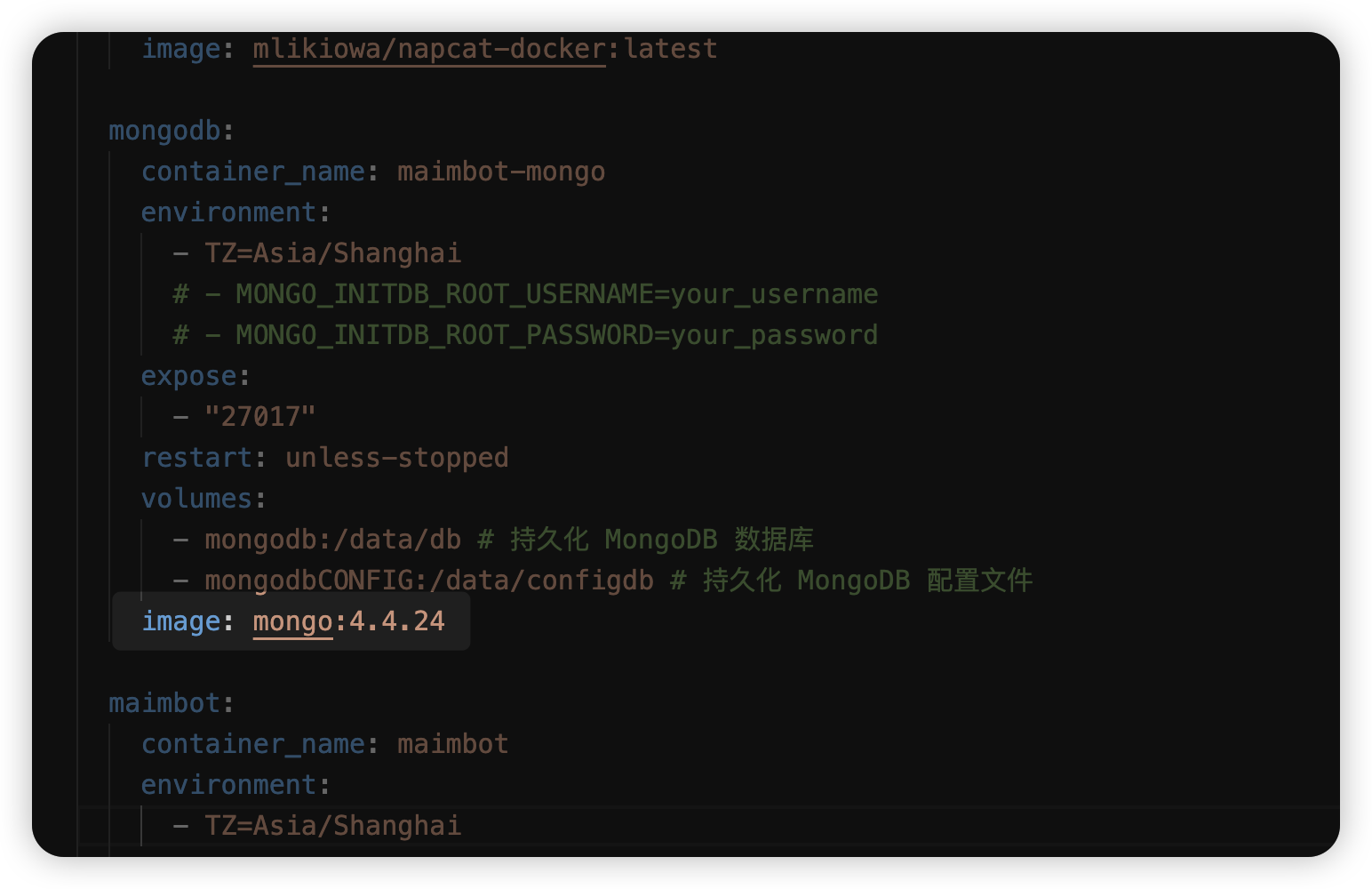
下载后打开,将 `services-mongodb-image` 修改为 `mongo:4.4.24`。这是因为最新的 MongoDB 强制要求 AVX 指令集,而群晖似乎不支持这个指令集
|
||||||
|
|
||||||
|
|
||||||
|
bot_config.toml: https://github.com/SengokuCola/MaiMBot/blob/main/template/bot_config_template.toml
|
||||||
|
下载后,重命名为 `bot_config.toml`
|
||||||
|
打开它,按自己的需求填写配置文件
|
||||||
|
|
||||||
|
.env.prod: https://github.com/SengokuCola/MaiMBot/blob/main/template.env
|
||||||
|
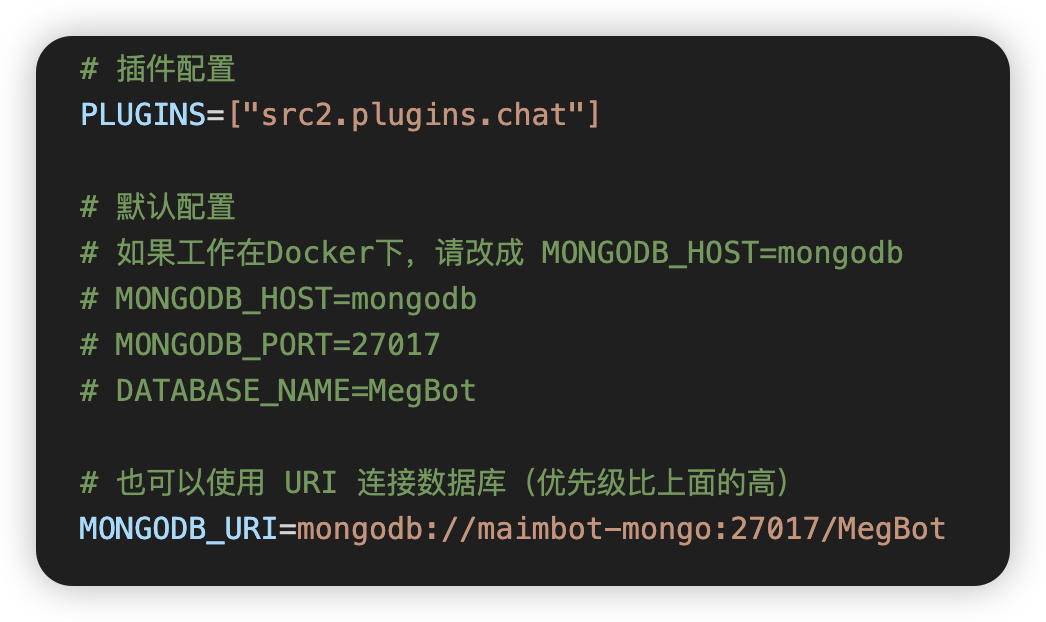
下载后,重命名为 `.env.prod`
|
||||||
|
按下图修改 mongodb 设置,使用 `MONGODB_URI`
|
||||||
|
|
||||||
|
|
||||||
|
把 `bot_config.toml` 和 `.env.prod` 放入之前创建的 `MaiMBot`文件夹
|
||||||
|
|
||||||
|
#### 如何下载?
|
||||||
|
|
||||||
|
点这里!
|
||||||
|
|
||||||
|
### 创建项目
|
||||||
|
|
||||||
|
打开 `DSM ➡️ ContainerManager ➡️ 项目`,点击 `新增` 创建项目,填写以下内容:
|
||||||
|
|
||||||
|
- 项目名称: `maimbot`
|
||||||
|
- 路径:之前创建的 `MaiMBot` 文件夹
|
||||||
|
- 来源: `上传 docker-compose.yml`
|
||||||
|
- 文件:之前下载的 `docker-compose.yml` 文件
|
||||||
|
|
||||||
|
图例:
|
||||||
|
|
||||||
|
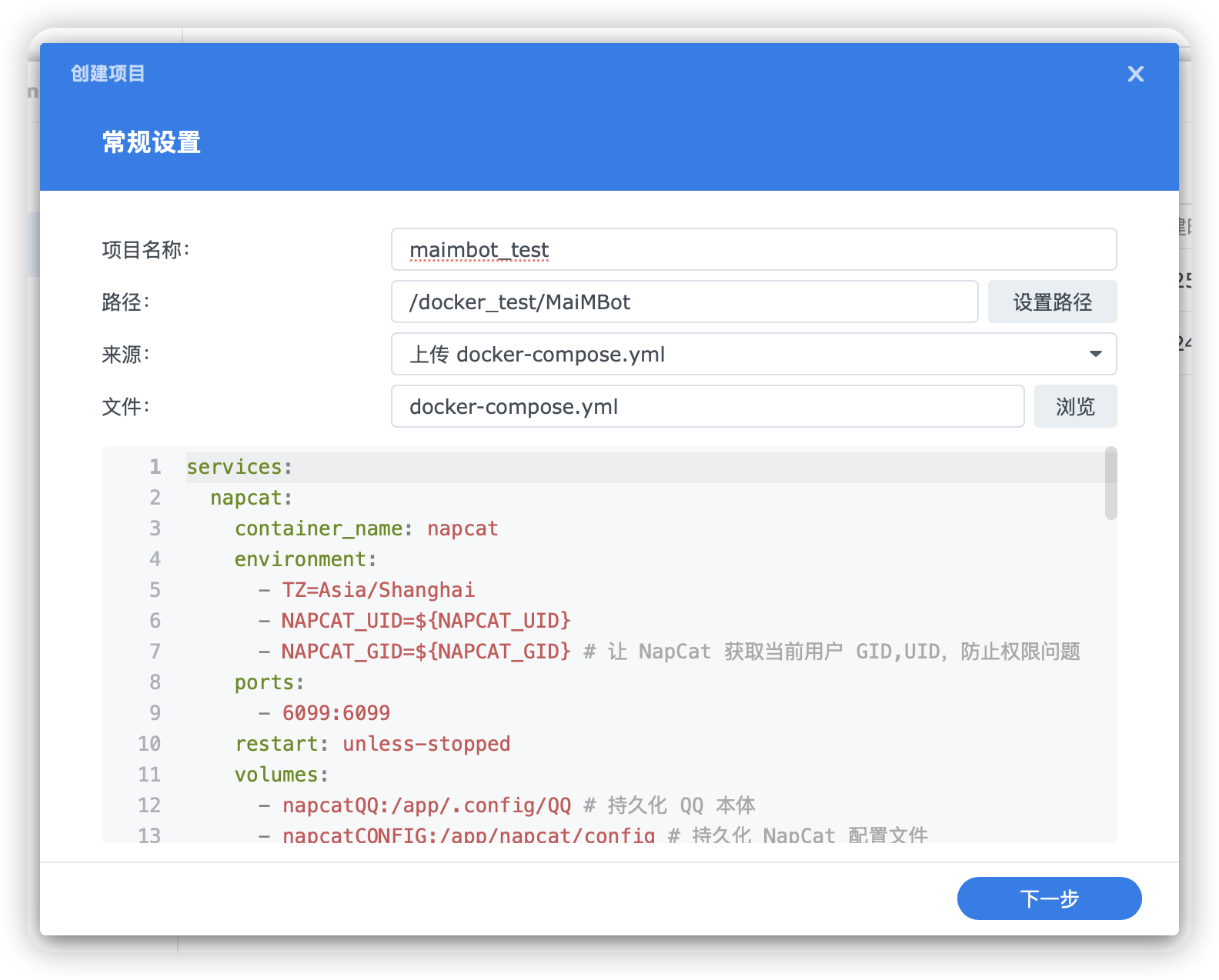
|
||||||
|
|
||||||
|
一路点下一步,等待项目创建完成
|
||||||
|
|
||||||
|
### 设置 Napcat
|
||||||
|
|
||||||
|
1. 登陆 napcat
|
||||||
|
打开 napcat: `http://<你的nas地址>:6099` ,输入token登陆
|
||||||
|
token可以打开 `DSM ➡️ ContainerManager ➡️ 项目 ➡️ MaiMBot ➡️ 容器 ➡️ Napcat ➡️ 日志`,找到类似 `[WebUi] WebUi Local Panel Url: http://127.0.0.1:6099/webui?token=xxxx` 的日志
|
||||||
|
这个 `token=` 后面的就是你的 napcat token
|
||||||
|
|
||||||
|
2. 按提示,登陆你给麦麦准备的QQ小号
|
||||||
|
|
||||||
|
3. 设置 websocket 客户端
|
||||||
|
`网络配置 -> 新建 -> Websocket客户端`,名称自定,URL栏填入 `ws://maimbot:8080/onebot/v11/ws`,启用并保存即可。
|
||||||
|
若修改过容器名称,则替换 `maimbot` 为你自定的名称
|
||||||
|
|
||||||
|
### 部署完成
|
||||||
|
|
||||||
|
找个群,发送 `麦麦,你在吗` 之类的
|
||||||
|
如果一切正常,应该能正常回复了
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 170 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 133 KiB |
|
|
@ -0,0 +1,278 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
# Maimbot 一键安装脚本 by Cookie987
|
||||||
|
# 适用于Debian系
|
||||||
|
# 请小心使用任何一键脚本!
|
||||||
|
|
||||||
|
# 如无法访问GitHub请修改此处镜像地址
|
||||||
|
|
||||||
|
LANG=C.UTF-8
|
||||||
|
|
||||||
|
GITHUB_REPO="https://ghfast.top/https://github.com/SengokuCola/MaiMBot.git"
|
||||||
|
|
||||||
|
# 颜色输出
|
||||||
|
GREEN="\e[32m"
|
||||||
|
RED="\e[31m"
|
||||||
|
RESET="\e[0m"
|
||||||
|
|
||||||
|
# 需要的基本软件包
|
||||||
|
REQUIRED_PACKAGES=("git" "sudo" "python3" "python3-venv" "curl" "gnupg" "python3-pip")
|
||||||
|
|
||||||
|
# 默认项目目录
|
||||||
|
DEFAULT_INSTALL_DIR="/opt/maimbot"
|
||||||
|
|
||||||
|
# 服务名称
|
||||||
|
SERVICE_NAME="maimbot"
|
||||||
|
|
||||||
|
IS_INSTALL_MONGODB=false
|
||||||
|
IS_INSTALL_NAPCAT=false
|
||||||
|
|
||||||
|
# 1/6: 检测是否安装 whiptail
|
||||||
|
if ! command -v whiptail &>/dev/null; then
|
||||||
|
echo -e "${RED}[1/6] whiptail 未安装,正在安装...${RESET}"
|
||||||
|
apt update && apt install -y whiptail
|
||||||
|
fi
|
||||||
|
|
||||||
|
get_os_info() {
|
||||||
|
if command -v lsb_release &>/dev/null; then
|
||||||
|
OS_INFO=$(lsb_release -d | cut -f2)
|
||||||
|
elif [[ -f /etc/os-release ]]; then
|
||||||
|
OS_INFO=$(grep "^PRETTY_NAME=" /etc/os-release | cut -d '"' -f2)
|
||||||
|
else
|
||||||
|
OS_INFO="Unknown OS"
|
||||||
|
fi
|
||||||
|
echo "$OS_INFO"
|
||||||
|
}
|
||||||
|
|
||||||
|
# 检查系统
|
||||||
|
check_system() {
|
||||||
|
# 检查是否为 root 用户
|
||||||
|
if [[ "$(id -u)" -ne 0 ]]; then
|
||||||
|
whiptail --title "🚫 权限不足" --msgbox "请使用 root 用户运行此脚本!\n执行方式: sudo bash $0" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ -f /etc/os-release ]]; then
|
||||||
|
source /etc/os-release
|
||||||
|
if [[ "$ID" != "debian" || "$VERSION_ID" != "12" ]]; then
|
||||||
|
whiptail --title "🚫 不支持的系统" --msgbox "此脚本仅支持 Debian 12 (Bookworm)!\n当前系统: $PRETTY_NAME\n安装已终止。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
else
|
||||||
|
whiptail --title "⚠️ 无法检测系统" --msgbox "无法识别系统版本,安装已终止。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 3/6: 询问用户是否安装缺失的软件包
|
||||||
|
install_packages() {
|
||||||
|
missing_packages=()
|
||||||
|
for package in "${REQUIRED_PACKAGES[@]}"; do
|
||||||
|
if ! dpkg -s "$package" &>/dev/null; then
|
||||||
|
missing_packages+=("$package")
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到以下必须的依赖项目缺失:\n${missing_packages[*]}\n\n是否要自动安装?" 12 60
|
||||||
|
if [[ $? -eq 0 ]]; then
|
||||||
|
return 0
|
||||||
|
else
|
||||||
|
whiptail --title "⚠️ 注意" --yesno "某些必要的依赖项未安装,可能会影响运行!\n是否继续?" 10 60 || exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 4/6: Python 版本检查
|
||||||
|
check_python() {
|
||||||
|
PYTHON_VERSION=$(python3 -c 'import sys; print(f"{sys.version_info.major}.{sys.version_info.minor}")')
|
||||||
|
|
||||||
|
python3 -c "import sys; exit(0) if sys.version_info >= (3,9) else exit(1)"
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
whiptail --title "⚠️ [4/6] Python 版本过低" --msgbox "检测到 Python 版本为 $PYTHON_VERSION,需要 3.9 或以上!\n请升级 Python 后重新运行本脚本。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 5/6: 选择分支
|
||||||
|
choose_branch() {
|
||||||
|
BRANCH=$(whiptail --title "🔀 [5/6] 选择 Maimbot 分支" --menu "请选择要安装的 Maimbot 分支:" 15 60 2 \
|
||||||
|
"main" "稳定版本(推荐)" \
|
||||||
|
"debug" "开发版本(可能不稳定)" 3>&1 1>&2 2>&3)
|
||||||
|
|
||||||
|
if [[ -z "$BRANCH" ]]; then
|
||||||
|
BRANCH="main"
|
||||||
|
whiptail --title "🔀 默认选择" --msgbox "未选择分支,默认安装稳定版本(main)" 10 60
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 6/6: 选择安装路径
|
||||||
|
choose_install_dir() {
|
||||||
|
INSTALL_DIR=$(whiptail --title "📂 [6/6] 选择安装路径" --inputbox "请输入 Maimbot 的安装目录:" 10 60 "$DEFAULT_INSTALL_DIR" 3>&1 1>&2 2>&3)
|
||||||
|
|
||||||
|
if [[ -z "$INSTALL_DIR" ]]; then
|
||||||
|
whiptail --title "⚠️ 取消输入" --yesno "未输入安装路径,是否退出安装?" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
INSTALL_DIR="$DEFAULT_INSTALL_DIR"
|
||||||
|
else
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 显示确认界面
|
||||||
|
confirm_install() {
|
||||||
|
local confirm_message="请确认以下更改:\n\n"
|
||||||
|
|
||||||
|
if [[ ${#missing_packages[@]} -gt 0 ]]; then
|
||||||
|
confirm_message+="📦 安装缺失的依赖项: ${missing_packages[*]}\n"
|
||||||
|
else
|
||||||
|
confirm_message+="✅ 所有依赖项已安装\n"
|
||||||
|
fi
|
||||||
|
|
||||||
|
confirm_message+="📂 安装麦麦Bot到: $INSTALL_DIR\n"
|
||||||
|
confirm_message+="🔀 分支: $BRANCH\n"
|
||||||
|
|
||||||
|
if [[ "$MONGODB_INSTALLED" == "true" ]]; then
|
||||||
|
confirm_message+="✅ MongoDB 已安装\n"
|
||||||
|
else
|
||||||
|
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||||
|
confirm_message+="📦 安装 MongoDB\n"
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||||
|
confirm_message+="✅ NapCat 已安装\n"
|
||||||
|
else
|
||||||
|
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||||
|
confirm_message+="📦 安装 NapCat\n"
|
||||||
|
fi
|
||||||
|
fi
|
||||||
|
|
||||||
|
confirm_message+="🛠️ 添加麦麦Bot作为系统服务 ($SERVICE_NAME.service)\n"
|
||||||
|
|
||||||
|
confitm_message+="\n\n注意:本脚本默认使用ghfast.top为GitHub进行加速,如不想使用请手动修改脚本开头的GITHUB_REPO变量。"
|
||||||
|
whiptail --title "🔧 安装确认" --yesno "$confirm_message\n\n是否继续安装?" 15 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
whiptail --title "🚫 取消安装" --msgbox "安装已取消。" 10 60
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
check_mongodb() {
|
||||||
|
if command -v mongod &>/dev/null; then
|
||||||
|
MONGO_INSTALLED=true
|
||||||
|
else
|
||||||
|
MONGO_INSTALLED=false
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
# 安装 MongoDB
|
||||||
|
install_mongodb() {
|
||||||
|
if [[ "$MONGO_INSTALLED" == "true" ]]; then
|
||||||
|
return 0
|
||||||
|
fi
|
||||||
|
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装MongoDB,是否安装?\n如果您想使用远程数据库,请跳过此步。" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
return 1
|
||||||
|
fi
|
||||||
|
IS_INSTALL_MONGODB=true
|
||||||
|
}
|
||||||
|
|
||||||
|
check_napcat() {
|
||||||
|
if command -v napcat &>/dev/null; then
|
||||||
|
NAPCAT_INSTALLED=true
|
||||||
|
else
|
||||||
|
NAPCAT_INSTALLED=false
|
||||||
|
fi
|
||||||
|
}
|
||||||
|
|
||||||
|
install_napcat() {
|
||||||
|
if [[ "$NAPCAT_INSTALLED" == "true" ]]; then
|
||||||
|
return 0
|
||||||
|
fi
|
||||||
|
|
||||||
|
whiptail --title "📦 [3/6] 软件包检查" --yesno "检测到未安装NapCat,是否安装?\n如果您想使用远程NapCat,请跳过此步。" 10 60
|
||||||
|
if [[ $? -ne 0 ]]; then
|
||||||
|
return 1
|
||||||
|
fi
|
||||||
|
IS_INSTALL_NAPCAT=true
|
||||||
|
}
|
||||||
|
|
||||||
|
# 运行安装步骤
|
||||||
|
check_system
|
||||||
|
check_mongodb
|
||||||
|
check_napcat
|
||||||
|
install_packages
|
||||||
|
install_mongodb
|
||||||
|
install_napcat
|
||||||
|
check_python
|
||||||
|
choose_branch
|
||||||
|
choose_install_dir
|
||||||
|
confirm_install
|
||||||
|
|
||||||
|
# 开始安装
|
||||||
|
whiptail --title "🚀 开始安装" --msgbox "所有环境检查完毕,即将开始安装麦麦Bot!" 10 60
|
||||||
|
|
||||||
|
echo -e "${GREEN}安装依赖项...${RESET}"
|
||||||
|
|
||||||
|
apt update && apt install -y "${missing_packages[@]}"
|
||||||
|
|
||||||
|
|
||||||
|
if [[ "$IS_INSTALL_MONGODB" == "true" ]]; then
|
||||||
|
echo -e "${GREEN}安装 MongoDB...${RESET}"
|
||||||
|
curl -fsSL https://www.mongodb.org/static/pgp/server-8.0.asc | gpg -o /usr/share/keyrings/mongodb-server-8.0.gpg --dearmor
|
||||||
|
echo "deb [ signed-by=/usr/share/keyrings/mongodb-server-8.0.gpg ] http://repo.mongodb.org/apt/debian bookworm/mongodb-org/8.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-8.0.list
|
||||||
|
apt-get update
|
||||||
|
apt-get install -y mongodb-org
|
||||||
|
|
||||||
|
systemctl enable mongod
|
||||||
|
systemctl start mongod
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [[ "$IS_INSTALL_NAPCAT" == "true" ]]; then
|
||||||
|
echo -e "${GREEN}安装 NapCat...${RESET}"
|
||||||
|
curl -o napcat.sh https://nclatest.znin.net/NapNeko/NapCat-Installer/main/script/install.sh && bash napcat.sh
|
||||||
|
fi
|
||||||
|
|
||||||
|
echo -e "${GREEN}创建 Python 虚拟环境...${RESET}"
|
||||||
|
mkdir -p "$INSTALL_DIR"
|
||||||
|
cd "$INSTALL_DIR" || exit
|
||||||
|
python3 -m venv venv
|
||||||
|
source venv/bin/activate
|
||||||
|
|
||||||
|
echo -e "${GREEN}克隆仓库...${RESET}"
|
||||||
|
# 安装 Maimbot
|
||||||
|
mkdir -p "$INSTALL_DIR/repo"
|
||||||
|
cd "$INSTALL_DIR/repo" || exit 1
|
||||||
|
git clone -b "$BRANCH" $GITHUB_REPO .
|
||||||
|
|
||||||
|
echo -e "${GREEN}安装 Python 依赖...${RESET}"
|
||||||
|
pip install -r requirements.txt
|
||||||
|
|
||||||
|
echo -e "${GREEN}设置服务...${RESET}"
|
||||||
|
|
||||||
|
# 设置 Maimbot 服务
|
||||||
|
cat <<EOF | tee /etc/systemd/system/$SERVICE_NAME.service
|
||||||
|
[Unit]
|
||||||
|
Description=MaiMbot 麦麦
|
||||||
|
After=network.target mongod.service
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type=simple
|
||||||
|
WorkingDirectory=$INSTALL_DIR/repo/
|
||||||
|
ExecStart=$INSTALL_DIR/venv/bin/python3 bot.py
|
||||||
|
ExecStop=/bin/kill -2 $MAINPID
|
||||||
|
Restart=always
|
||||||
|
RestartSec=10s
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=multi-user.target
|
||||||
|
EOF
|
||||||
|
|
||||||
|
systemctl daemon-reload
|
||||||
|
systemctl enable maimbot
|
||||||
|
systemctl start maimbot
|
||||||
|
|
||||||
|
whiptail --title "🎉 安装完成" --msgbox "麦麦Bot安装完成!\n已经启动麦麦Bot服务。\n\n安装路径: $INSTALL_DIR\n分支: $BRANCH" 12 60
|
||||||
|
|
@ -1,73 +1,51 @@
|
||||||
from typing import Optional
|
import os
|
||||||
|
from typing import cast
|
||||||
from pymongo import MongoClient
|
from pymongo import MongoClient
|
||||||
from pymongo.database import Database as MongoDatabase
|
from pymongo.database import Database
|
||||||
|
|
||||||
class Database:
|
_client = None
|
||||||
_instance: Optional["Database"] = None
|
_db = None
|
||||||
|
|
||||||
def __init__(
|
|
||||||
self,
|
|
||||||
host: str,
|
|
||||||
port: int,
|
|
||||||
db_name: str,
|
|
||||||
username: Optional[str] = None,
|
|
||||||
password: Optional[str] = None,
|
|
||||||
auth_source: Optional[str] = None,
|
|
||||||
uri: Optional[str] = None,
|
|
||||||
):
|
|
||||||
if uri and uri.startswith("mongodb://"):
|
|
||||||
# 优先使用URI连接
|
|
||||||
self.client = MongoClient(uri)
|
|
||||||
elif username and password:
|
|
||||||
# 如果有用户名和密码,使用认证连接
|
|
||||||
self.client = MongoClient(
|
|
||||||
host, port, username=username, password=password, authSource=auth_source
|
|
||||||
)
|
|
||||||
else:
|
|
||||||
# 否则使用无认证连接
|
|
||||||
self.client = MongoClient(host, port)
|
|
||||||
self.db: MongoDatabase = self.client[db_name]
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def initialize(
|
|
||||||
cls,
|
|
||||||
host: str,
|
|
||||||
port: int,
|
|
||||||
db_name: str,
|
|
||||||
username: Optional[str] = None,
|
|
||||||
password: Optional[str] = None,
|
|
||||||
auth_source: Optional[str] = None,
|
|
||||||
uri: Optional[str] = None,
|
|
||||||
) -> MongoDatabase:
|
|
||||||
if cls._instance is None:
|
|
||||||
cls._instance = cls(
|
|
||||||
host, port, db_name, username, password, auth_source, uri
|
|
||||||
)
|
|
||||||
return cls._instance.db
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def get_instance(cls) -> MongoDatabase:
|
|
||||||
if cls._instance is None:
|
|
||||||
raise RuntimeError("Database not initialized")
|
|
||||||
return cls._instance.db
|
|
||||||
|
|
||||||
|
|
||||||
#测试用
|
def __create_database_instance():
|
||||||
|
uri = os.getenv("MONGODB_URI")
|
||||||
def get_random_group_messages(self, group_id: str, limit: int = 5):
|
host = os.getenv("MONGODB_HOST", "127.0.0.1")
|
||||||
# 先随机获取一条消息
|
port = int(os.getenv("MONGODB_PORT", "27017"))
|
||||||
random_message = list(self.db.messages.aggregate([
|
db_name = os.getenv("DATABASE_NAME", "MegBot")
|
||||||
{"$match": {"group_id": group_id}},
|
username = os.getenv("MONGODB_USERNAME")
|
||||||
{"$sample": {"size": 1}}
|
password = os.getenv("MONGODB_PASSWORD")
|
||||||
]))[0]
|
auth_source = os.getenv("MONGODB_AUTH_SOURCE")
|
||||||
|
|
||||||
# 获取该消息之后的消息
|
if uri and uri.startswith("mongodb://"):
|
||||||
subsequent_messages = list(self.db.messages.find({
|
# 优先使用URI连接
|
||||||
"group_id": group_id,
|
return MongoClient(uri)
|
||||||
"time": {"$gt": random_message["time"]}
|
|
||||||
}).sort("time", 1).limit(limit))
|
if username and password:
|
||||||
|
# 如果有用户名和密码,使用认证连接
|
||||||
# 将随机消息和后续消息合并
|
return MongoClient(host, port, username=username, password=password, authSource=auth_source)
|
||||||
messages = [random_message] + subsequent_messages
|
|
||||||
|
# 否则使用无认证连接
|
||||||
return messages
|
return MongoClient(host, port)
|
||||||
|
|
||||||
|
|
||||||
|
def get_db():
|
||||||
|
"""获取数据库连接实例,延迟初始化。"""
|
||||||
|
global _client, _db
|
||||||
|
if _client is None:
|
||||||
|
_client = __create_database_instance()
|
||||||
|
_db = _client[os.getenv("DATABASE_NAME", "MegBot")]
|
||||||
|
return _db
|
||||||
|
|
||||||
|
|
||||||
|
class DBWrapper:
|
||||||
|
"""数据库代理类,保持接口兼容性同时实现懒加载。"""
|
||||||
|
|
||||||
|
def __getattr__(self, name):
|
||||||
|
return getattr(get_db(), name)
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
return get_db()[key]
|
||||||
|
|
||||||
|
|
||||||
|
# 全局数据库访问点
|
||||||
|
db: Database = DBWrapper()
|
||||||
|
|
|
||||||
|
|
@ -7,7 +7,7 @@ from datetime import datetime
|
||||||
from typing import Dict, List
|
from typing import Dict, List
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
from ..common.database import Database
|
|
||||||
|
|
||||||
import customtkinter as ctk
|
import customtkinter as ctk
|
||||||
from dotenv import load_dotenv
|
from dotenv import load_dotenv
|
||||||
|
|
@ -16,6 +16,8 @@ from dotenv import load_dotenv
|
||||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||||
# 获取项目根目录
|
# 获取项目根目录
|
||||||
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..'))
|
root_dir = os.path.abspath(os.path.join(current_dir, '..', '..'))
|
||||||
|
sys.path.insert(0, root_dir)
|
||||||
|
from src.common.database import db
|
||||||
|
|
||||||
# 加载环境变量
|
# 加载环境变量
|
||||||
if os.path.exists(os.path.join(root_dir, '.env.dev')):
|
if os.path.exists(os.path.join(root_dir, '.env.dev')):
|
||||||
|
|
@ -44,28 +46,6 @@ class ReasoningGUI:
|
||||||
self.root.geometry('800x600')
|
self.root.geometry('800x600')
|
||||||
self.root.protocol("WM_DELETE_WINDOW", self._on_closing)
|
self.root.protocol("WM_DELETE_WINDOW", self._on_closing)
|
||||||
|
|
||||||
# 初始化数据库连接
|
|
||||||
try:
|
|
||||||
self.db = Database.get_instance()
|
|
||||||
logger.success("数据库连接成功")
|
|
||||||
except RuntimeError:
|
|
||||||
logger.warning("数据库未初始化,正在尝试初始化...")
|
|
||||||
try:
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
self.db = Database.get_instance()
|
|
||||||
logger.success("数据库初始化成功")
|
|
||||||
except Exception:
|
|
||||||
logger.exception("数据库初始化失败")
|
|
||||||
sys.exit(1)
|
|
||||||
|
|
||||||
# 存储群组数据
|
# 存储群组数据
|
||||||
self.group_data: Dict[str, List[dict]] = {}
|
self.group_data: Dict[str, List[dict]] = {}
|
||||||
|
|
||||||
|
|
@ -264,11 +244,11 @@ class ReasoningGUI:
|
||||||
logger.debug(f"查询条件: {query}")
|
logger.debug(f"查询条件: {query}")
|
||||||
|
|
||||||
# 先获取一条记录检查时间格式
|
# 先获取一条记录检查时间格式
|
||||||
sample = self.db.reasoning_logs.find_one()
|
sample = db.reasoning_logs.find_one()
|
||||||
if sample:
|
if sample:
|
||||||
logger.debug(f"样本记录时间格式: {type(sample['time'])} 值: {sample['time']}")
|
logger.debug(f"样本记录时间格式: {type(sample['time'])} 值: {sample['time']}")
|
||||||
|
|
||||||
cursor = self.db.reasoning_logs.find(query).sort("time", -1)
|
cursor = db.reasoning_logs.find(query).sort("time", -1)
|
||||||
new_data = {}
|
new_data = {}
|
||||||
total_count = 0
|
total_count = 0
|
||||||
|
|
||||||
|
|
@ -333,17 +313,6 @@ class ReasoningGUI:
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
"""主函数"""
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
|
|
||||||
app = ReasoningGUI()
|
app = ReasoningGUI()
|
||||||
app.run()
|
app.run()
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -3,11 +3,11 @@ import time
|
||||||
import os
|
import os
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver, on_message, require
|
from nonebot import get_driver, on_message, on_notice, require
|
||||||
from nonebot.adapters.onebot.v11 import Bot, GroupMessageEvent, Message, MessageSegment,MessageEvent
|
from nonebot.rule import to_me
|
||||||
|
from nonebot.adapters.onebot.v11 import Bot, GroupMessageEvent, Message, MessageSegment, MessageEvent, NoticeEvent
|
||||||
from nonebot.typing import T_State
|
from nonebot.typing import T_State
|
||||||
|
|
||||||
from ...common.database import Database
|
|
||||||
from ..moods.moods import MoodManager # 导入情绪管理器
|
from ..moods.moods import MoodManager # 导入情绪管理器
|
||||||
from ..schedule.schedule_generator import bot_schedule
|
from ..schedule.schedule_generator import bot_schedule
|
||||||
from ..utils.statistic import LLMStatistics
|
from ..utils.statistic import LLMStatistics
|
||||||
|
|
@ -40,6 +40,8 @@ logger.debug(f"正在唤醒{global_config.BOT_NICKNAME}......")
|
||||||
chat_bot = ChatBot()
|
chat_bot = ChatBot()
|
||||||
# 注册消息处理器
|
# 注册消息处理器
|
||||||
msg_in = on_message(priority=5)
|
msg_in = on_message(priority=5)
|
||||||
|
# 注册和bot相关的通知处理器
|
||||||
|
notice_matcher = on_notice(priority=1)
|
||||||
# 创建定时任务
|
# 创建定时任务
|
||||||
scheduler = require("nonebot_plugin_apscheduler").scheduler
|
scheduler = require("nonebot_plugin_apscheduler").scheduler
|
||||||
|
|
||||||
|
|
@ -96,19 +98,24 @@ async def _(bot: Bot, event: MessageEvent, state: T_State):
|
||||||
await chat_bot.handle_message(event, bot)
|
await chat_bot.handle_message(event, bot)
|
||||||
|
|
||||||
|
|
||||||
|
@notice_matcher.handle()
|
||||||
|
async def _(bot: Bot, event: NoticeEvent, state: T_State):
|
||||||
|
logger.debug(f"收到通知:{event}")
|
||||||
|
await chat_bot.handle_notice(event, bot)
|
||||||
|
|
||||||
|
|
||||||
# 添加build_memory定时任务
|
# 添加build_memory定时任务
|
||||||
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval, id="build_memory")
|
@scheduler.scheduled_job("interval", seconds=global_config.build_memory_interval, id="build_memory")
|
||||||
async def build_memory_task():
|
async def build_memory_task():
|
||||||
"""每build_memory_interval秒执行一次记忆构建"""
|
"""每build_memory_interval秒执行一次记忆构建"""
|
||||||
logger.debug(
|
logger.debug("[记忆构建]------------------------------------开始构建记忆--------------------------------------")
|
||||||
"[记忆构建]"
|
|
||||||
"------------------------------------开始构建记忆--------------------------------------")
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
await hippocampus.operation_build_memory(chat_size=20)
|
await hippocampus.operation_build_memory(chat_size=20)
|
||||||
end_time = time.time()
|
end_time = time.time()
|
||||||
logger.success(
|
logger.success(
|
||||||
f"[记忆构建]--------------------------记忆构建完成:耗时: {end_time - start_time:.2f} "
|
f"[记忆构建]--------------------------记忆构建完成:耗时: {end_time - start_time:.2f} "
|
||||||
"秒-------------------------------------------")
|
"秒-------------------------------------------"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
@scheduler.scheduled_job("interval", seconds=global_config.forget_memory_interval, id="forget_memory")
|
@scheduler.scheduled_job("interval", seconds=global_config.forget_memory_interval, id="forget_memory")
|
||||||
|
|
@ -132,3 +139,12 @@ async def print_mood_task():
|
||||||
"""每30秒打印一次情绪状态"""
|
"""每30秒打印一次情绪状态"""
|
||||||
mood_manager = MoodManager.get_instance()
|
mood_manager = MoodManager.get_instance()
|
||||||
mood_manager.print_mood_status()
|
mood_manager.print_mood_status()
|
||||||
|
|
||||||
|
|
||||||
|
@scheduler.scheduled_job("interval", seconds=7200, id="generate_schedule")
|
||||||
|
async def generate_schedule_task():
|
||||||
|
"""每2小时尝试生成一次日程"""
|
||||||
|
logger.debug("尝试生成日程")
|
||||||
|
await bot_schedule.initialize()
|
||||||
|
if not bot_schedule.enable_output:
|
||||||
|
bot_schedule.print_schedule()
|
||||||
|
|
|
||||||
|
|
@ -7,6 +7,8 @@ from nonebot.adapters.onebot.v11 import (
|
||||||
GroupMessageEvent,
|
GroupMessageEvent,
|
||||||
MessageEvent,
|
MessageEvent,
|
||||||
PrivateMessageEvent,
|
PrivateMessageEvent,
|
||||||
|
NoticeEvent,
|
||||||
|
PokeNotifyEvent,
|
||||||
)
|
)
|
||||||
|
|
||||||
from ..memory_system.memory import hippocampus
|
from ..memory_system.memory import hippocampus
|
||||||
|
|
@ -25,6 +27,7 @@ from .relationship_manager import relationship_manager
|
||||||
from .storage import MessageStorage
|
from .storage import MessageStorage
|
||||||
from .utils import calculate_typing_time, is_mentioned_bot_in_message
|
from .utils import calculate_typing_time, is_mentioned_bot_in_message
|
||||||
from .utils_image import image_path_to_base64
|
from .utils_image import image_path_to_base64
|
||||||
|
from .utils_user import get_user_nickname, get_user_cardname, get_groupname
|
||||||
from .willing_manager import willing_manager # 导入意愿管理器
|
from .willing_manager import willing_manager # 导入意愿管理器
|
||||||
from .message_base import UserInfo, GroupInfo, Seg
|
from .message_base import UserInfo, GroupInfo, Seg
|
||||||
|
|
||||||
|
|
@ -46,6 +49,69 @@ class ChatBot:
|
||||||
if not self._started:
|
if not self._started:
|
||||||
self._started = True
|
self._started = True
|
||||||
|
|
||||||
|
async def handle_notice(self, event: NoticeEvent, bot: Bot) -> None:
|
||||||
|
"""处理收到的通知"""
|
||||||
|
# 戳一戳通知
|
||||||
|
if isinstance(event, PokeNotifyEvent):
|
||||||
|
# 用户屏蔽,不区分私聊/群聊
|
||||||
|
if event.user_id in global_config.ban_user_id:
|
||||||
|
return
|
||||||
|
reply_poke_probability = 1 # 回复戳一戳的概率
|
||||||
|
|
||||||
|
if random() < reply_poke_probability:
|
||||||
|
user_info = UserInfo(
|
||||||
|
user_id=event.user_id,
|
||||||
|
user_nickname=get_user_nickname(event.user_id) or None,
|
||||||
|
user_cardname=get_user_cardname(event.user_id) or None,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
group_info = GroupInfo(group_id=event.group_id, group_name=None, platform="qq")
|
||||||
|
message_cq = MessageRecvCQ(
|
||||||
|
message_id=None,
|
||||||
|
user_info=user_info,
|
||||||
|
raw_message=str("[戳了戳]你"),
|
||||||
|
group_info=group_info,
|
||||||
|
reply_message=None,
|
||||||
|
platform="qq",
|
||||||
|
)
|
||||||
|
message_json = message_cq.to_dict()
|
||||||
|
|
||||||
|
# 进入maimbot
|
||||||
|
message = MessageRecv(message_json)
|
||||||
|
groupinfo = message.message_info.group_info
|
||||||
|
userinfo = message.message_info.user_info
|
||||||
|
messageinfo = message.message_info
|
||||||
|
|
||||||
|
chat = await chat_manager.get_or_create_stream(
|
||||||
|
platform=messageinfo.platform, user_info=userinfo, group_info=groupinfo
|
||||||
|
)
|
||||||
|
message.update_chat_stream(chat)
|
||||||
|
await message.process()
|
||||||
|
|
||||||
|
bot_user_info = UserInfo(
|
||||||
|
user_id=global_config.BOT_QQ,
|
||||||
|
user_nickname=global_config.BOT_NICKNAME,
|
||||||
|
platform=messageinfo.platform,
|
||||||
|
)
|
||||||
|
|
||||||
|
response, raw_content = await self.gpt.generate_response(message)
|
||||||
|
|
||||||
|
if response:
|
||||||
|
for msg in response:
|
||||||
|
message_segment = Seg(type="text", data=msg)
|
||||||
|
|
||||||
|
bot_message = MessageSending(
|
||||||
|
message_id=None,
|
||||||
|
chat_stream=chat,
|
||||||
|
bot_user_info=bot_user_info,
|
||||||
|
sender_info=userinfo,
|
||||||
|
message_segment=message_segment,
|
||||||
|
reply=None,
|
||||||
|
is_head=False,
|
||||||
|
is_emoji=False,
|
||||||
|
)
|
||||||
|
message_manager.add_message(bot_message)
|
||||||
|
|
||||||
async def handle_message(self, event: MessageEvent, bot: Bot) -> None:
|
async def handle_message(self, event: MessageEvent, bot: Bot) -> None:
|
||||||
"""处理收到的消息"""
|
"""处理收到的消息"""
|
||||||
|
|
||||||
|
|
@ -54,7 +120,10 @@ class ChatBot:
|
||||||
# 用户屏蔽,不区分私聊/群聊
|
# 用户屏蔽,不区分私聊/群聊
|
||||||
if event.user_id in global_config.ban_user_id:
|
if event.user_id in global_config.ban_user_id:
|
||||||
return
|
return
|
||||||
|
|
||||||
|
if event.reply and hasattr(event.reply, 'sender') and hasattr(event.reply.sender, 'user_id') and event.reply.sender.user_id in global_config.ban_user_id:
|
||||||
|
logger.debug(f"跳过处理回复来自被ban用户 {event.reply.sender.user_id} 的消息")
|
||||||
|
return
|
||||||
# 处理私聊消息
|
# 处理私聊消息
|
||||||
if isinstance(event, PrivateMessageEvent):
|
if isinstance(event, PrivateMessageEvent):
|
||||||
if not global_config.enable_friend_chat: # 私聊过滤
|
if not global_config.enable_friend_chat: # 私聊过滤
|
||||||
|
|
@ -126,7 +195,7 @@ class ChatBot:
|
||||||
for word in global_config.ban_words:
|
for word in global_config.ban_words:
|
||||||
if word in message.processed_plain_text:
|
if word in message.processed_plain_text:
|
||||||
logger.info(
|
logger.info(
|
||||||
f"[{chat.group_info.group_name if chat.group_info.group_id else '私聊'}]{userinfo.user_nickname}:{message.processed_plain_text}"
|
f"[{chat.group_info.group_name if chat.group_info else '私聊'}]{userinfo.user_nickname}:{message.processed_plain_text}"
|
||||||
)
|
)
|
||||||
logger.info(f"[过滤词识别]消息中含有{word},filtered")
|
logger.info(f"[过滤词识别]消息中含有{word},filtered")
|
||||||
return
|
return
|
||||||
|
|
@ -135,7 +204,7 @@ class ChatBot:
|
||||||
for pattern in global_config.ban_msgs_regex:
|
for pattern in global_config.ban_msgs_regex:
|
||||||
if re.search(pattern, message.raw_message):
|
if re.search(pattern, message.raw_message):
|
||||||
logger.info(
|
logger.info(
|
||||||
f"[{chat.group_info.group_name if chat.group_info.group_id else '私聊'}]{message.user_nickname}:{message.raw_message}"
|
f"[{chat.group_info.group_name if chat.group_info else '私聊'}]{userinfo.user_nickname}:{message.raw_message}"
|
||||||
)
|
)
|
||||||
logger.info(f"[正则表达式过滤]消息匹配到{pattern},filtered")
|
logger.info(f"[正则表达式过滤]消息匹配到{pattern},filtered")
|
||||||
return
|
return
|
||||||
|
|
@ -143,7 +212,7 @@ class ChatBot:
|
||||||
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(messageinfo.time))
|
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(messageinfo.time))
|
||||||
|
|
||||||
# topic=await topic_identifier.identify_topic_llm(message.processed_plain_text)
|
# topic=await topic_identifier.identify_topic_llm(message.processed_plain_text)
|
||||||
|
|
||||||
topic = ""
|
topic = ""
|
||||||
interested_rate = await hippocampus.memory_activate_value(message.processed_plain_text) / 100
|
interested_rate = await hippocampus.memory_activate_value(message.processed_plain_text) / 100
|
||||||
logger.debug(f"对{message.processed_plain_text}的激活度:{interested_rate}")
|
logger.debug(f"对{message.processed_plain_text}的激活度:{interested_rate}")
|
||||||
|
|
@ -164,7 +233,7 @@ class ChatBot:
|
||||||
current_willing = willing_manager.get_willing(chat_stream=chat)
|
current_willing = willing_manager.get_willing(chat_stream=chat)
|
||||||
|
|
||||||
logger.info(
|
logger.info(
|
||||||
f"[{current_time}][{chat.group_info.group_name if chat.group_info.group_id else '私聊'}]{chat.user_info.user_nickname}:"
|
f"[{current_time}][{chat.group_info.group_name if chat.group_info else '私聊'}]{chat.user_info.user_nickname}:"
|
||||||
f"{message.processed_plain_text}[回复意愿:{current_willing:.2f}][概率:{reply_probability * 100:.1f}%]"
|
f"{message.processed_plain_text}[回复意愿:{current_willing:.2f}][概率:{reply_probability * 100:.1f}%]"
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -6,7 +6,7 @@ from typing import Dict, Optional
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from .message_base import GroupInfo, UserInfo
|
from .message_base import GroupInfo, UserInfo
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -83,7 +83,6 @@ class ChatManager:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
if not self._initialized:
|
if not self._initialized:
|
||||||
self.streams: Dict[str, ChatStream] = {} # stream_id -> ChatStream
|
self.streams: Dict[str, ChatStream] = {} # stream_id -> ChatStream
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._ensure_collection()
|
self._ensure_collection()
|
||||||
self._initialized = True
|
self._initialized = True
|
||||||
# 在事件循环中启动初始化
|
# 在事件循环中启动初始化
|
||||||
|
|
@ -111,11 +110,11 @@ class ChatManager:
|
||||||
|
|
||||||
def _ensure_collection(self):
|
def _ensure_collection(self):
|
||||||
"""确保数据库集合存在并创建索引"""
|
"""确保数据库集合存在并创建索引"""
|
||||||
if "chat_streams" not in self.db.list_collection_names():
|
if "chat_streams" not in db.list_collection_names():
|
||||||
self.db.create_collection("chat_streams")
|
db.create_collection("chat_streams")
|
||||||
# 创建索引
|
# 创建索引
|
||||||
self.db.chat_streams.create_index([("stream_id", 1)], unique=True)
|
db.chat_streams.create_index([("stream_id", 1)], unique=True)
|
||||||
self.db.chat_streams.create_index(
|
db.chat_streams.create_index(
|
||||||
[("platform", 1), ("user_info.user_id", 1), ("group_info.group_id", 1)]
|
[("platform", 1), ("user_info.user_id", 1), ("group_info.group_id", 1)]
|
||||||
)
|
)
|
||||||
|
|
||||||
|
|
@ -168,7 +167,7 @@ class ChatManager:
|
||||||
return stream
|
return stream
|
||||||
|
|
||||||
# 检查数据库中是否存在
|
# 检查数据库中是否存在
|
||||||
data = self.db.chat_streams.find_one({"stream_id": stream_id})
|
data = db.chat_streams.find_one({"stream_id": stream_id})
|
||||||
if data:
|
if data:
|
||||||
stream = ChatStream.from_dict(data)
|
stream = ChatStream.from_dict(data)
|
||||||
# 更新用户信息和群组信息
|
# 更新用户信息和群组信息
|
||||||
|
|
@ -204,7 +203,7 @@ class ChatManager:
|
||||||
async def _save_stream(self, stream: ChatStream):
|
async def _save_stream(self, stream: ChatStream):
|
||||||
"""保存聊天流到数据库"""
|
"""保存聊天流到数据库"""
|
||||||
if not stream.saved:
|
if not stream.saved:
|
||||||
self.db.chat_streams.update_one(
|
db.chat_streams.update_one(
|
||||||
{"stream_id": stream.stream_id}, {"$set": stream.to_dict()}, upsert=True
|
{"stream_id": stream.stream_id}, {"$set": stream.to_dict()}, upsert=True
|
||||||
)
|
)
|
||||||
stream.saved = True
|
stream.saved = True
|
||||||
|
|
@ -216,7 +215,7 @@ class ChatManager:
|
||||||
|
|
||||||
async def load_all_streams(self):
|
async def load_all_streams(self):
|
||||||
"""从数据库加载所有聊天流"""
|
"""从数据库加载所有聊天流"""
|
||||||
all_streams = self.db.chat_streams.find({})
|
all_streams = db.chat_streams.find({})
|
||||||
for data in all_streams:
|
for data in all_streams:
|
||||||
stream = ChatStream.from_dict(data)
|
stream = ChatStream.from_dict(data)
|
||||||
self.streams[stream.stream_id] = stream
|
self.streams[stream.stream_id] = stream
|
||||||
|
|
|
||||||
|
|
@ -86,9 +86,12 @@ class CQCode:
|
||||||
else:
|
else:
|
||||||
self.translated_segments = Seg(type="text", data="[图片]")
|
self.translated_segments = Seg(type="text", data="[图片]")
|
||||||
elif self.type == "at":
|
elif self.type == "at":
|
||||||
user_nickname = get_user_nickname(self.params.get("qq", ""))
|
if self.params.get("qq") == "all":
|
||||||
self.translated_segments = Seg(
|
self.translated_segments = Seg(type="text", data="@[全体成员]")
|
||||||
type="text", data=f"[@{user_nickname or '某人'}]"
|
else:
|
||||||
|
user_nickname = get_user_nickname(self.params.get("qq", ""))
|
||||||
|
self.translated_segments = Seg(
|
||||||
|
type="text", data=f"[@{user_nickname or '某人'}]"
|
||||||
)
|
)
|
||||||
elif self.type == "reply":
|
elif self.type == "reply":
|
||||||
reply_segments = self.translate_reply()
|
reply_segments = self.translate_reply()
|
||||||
|
|
|
||||||
|
|
@ -12,7 +12,7 @@ import io
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..chat.utils import get_embedding
|
from ..chat.utils import get_embedding
|
||||||
from ..chat.utils_image import ImageManager, image_path_to_base64
|
from ..chat.utils_image import ImageManager, image_path_to_base64
|
||||||
|
|
@ -25,22 +25,20 @@ image_manager = ImageManager()
|
||||||
|
|
||||||
class EmojiManager:
|
class EmojiManager:
|
||||||
_instance = None
|
_instance = None
|
||||||
EMOJI_DIR = "data/emoji" # 表情包存储目录
|
EMOJI_DIR = os.path.join("data", "emoji") # 表情包存储目录
|
||||||
|
|
||||||
def __new__(cls):
|
def __new__(cls):
|
||||||
if cls._instance is None:
|
if cls._instance is None:
|
||||||
cls._instance = super().__new__(cls)
|
cls._instance = super().__new__(cls)
|
||||||
cls._instance.db = None
|
|
||||||
cls._instance._initialized = False
|
cls._instance._initialized = False
|
||||||
return cls._instance
|
return cls._instance
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._scan_task = None
|
self._scan_task = None
|
||||||
self.vlm = LLM_request(model=global_config.vlm, temperature=0.3, max_tokens=1000)
|
self.vlm = LLM_request(model=global_config.vlm, temperature=0.3, max_tokens=1000)
|
||||||
self.llm_emotion_judge = LLM_request(model=global_config.llm_emotion_judge, max_tokens=60,
|
self.llm_emotion_judge = LLM_request(
|
||||||
temperature=0.8) # 更高的温度,更少的token(后续可以根据情绪来调整温度)
|
model=global_config.llm_emotion_judge, max_tokens=60, temperature=0.8
|
||||||
|
) # 更高的温度,更少的token(后续可以根据情绪来调整温度)
|
||||||
|
|
||||||
def _ensure_emoji_dir(self):
|
def _ensure_emoji_dir(self):
|
||||||
"""确保表情存储目录存在"""
|
"""确保表情存储目录存在"""
|
||||||
|
|
@ -50,7 +48,6 @@ class EmojiManager:
|
||||||
"""初始化数据库连接和表情目录"""
|
"""初始化数据库连接和表情目录"""
|
||||||
if not self._initialized:
|
if not self._initialized:
|
||||||
try:
|
try:
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._ensure_emoji_collection()
|
self._ensure_emoji_collection()
|
||||||
self._ensure_emoji_dir()
|
self._ensure_emoji_dir()
|
||||||
self._initialized = True
|
self._initialized = True
|
||||||
|
|
@ -68,42 +65,39 @@ class EmojiManager:
|
||||||
|
|
||||||
def _ensure_emoji_collection(self):
|
def _ensure_emoji_collection(self):
|
||||||
"""确保emoji集合存在并创建索引
|
"""确保emoji集合存在并创建索引
|
||||||
|
|
||||||
这个函数用于确保MongoDB数据库中存在emoji集合,并创建必要的索引。
|
这个函数用于确保MongoDB数据库中存在emoji集合,并创建必要的索引。
|
||||||
|
|
||||||
索引的作用是加快数据库查询速度:
|
索引的作用是加快数据库查询速度:
|
||||||
- embedding字段的2dsphere索引: 用于加速向量相似度搜索,帮助快速找到相似的表情包
|
- embedding字段的2dsphere索引: 用于加速向量相似度搜索,帮助快速找到相似的表情包
|
||||||
- tags字段的普通索引: 加快按标签搜索表情包的速度
|
- tags字段的普通索引: 加快按标签搜索表情包的速度
|
||||||
- filename字段的唯一索引: 确保文件名不重复,同时加快按文件名查找的速度
|
- filename字段的唯一索引: 确保文件名不重复,同时加快按文件名查找的速度
|
||||||
|
|
||||||
没有索引的话,数据库每次查询都需要扫描全部数据,建立索引后可以大大提高查询效率。
|
没有索引的话,数据库每次查询都需要扫描全部数据,建立索引后可以大大提高查询效率。
|
||||||
"""
|
"""
|
||||||
if 'emoji' not in self.db.list_collection_names():
|
if "emoji" not in db.list_collection_names():
|
||||||
self.db.create_collection('emoji')
|
db.create_collection("emoji")
|
||||||
self.db.emoji.create_index([('embedding', '2dsphere')])
|
db.emoji.create_index([("embedding", "2dsphere")])
|
||||||
self.db.emoji.create_index([('filename', 1)], unique=True)
|
db.emoji.create_index([("filename", 1)], unique=True)
|
||||||
|
|
||||||
def record_usage(self, emoji_id: str):
|
def record_usage(self, emoji_id: str):
|
||||||
"""记录表情使用次数"""
|
"""记录表情使用次数"""
|
||||||
try:
|
try:
|
||||||
self._ensure_db()
|
self._ensure_db()
|
||||||
self.db.emoji.update_one(
|
db.emoji.update_one({"_id": emoji_id}, {"$inc": {"usage_count": 1}})
|
||||||
{'_id': emoji_id},
|
|
||||||
{'$inc': {'usage_count': 1}}
|
|
||||||
)
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"记录表情使用失败: {str(e)}")
|
logger.error(f"记录表情使用失败: {str(e)}")
|
||||||
|
|
||||||
async def get_emoji_for_text(self, text: str) -> Optional[Tuple[str,str]]:
|
async def get_emoji_for_text(self, text: str) -> Optional[Tuple[str, str]]:
|
||||||
"""根据文本内容获取相关表情包
|
"""根据文本内容获取相关表情包
|
||||||
Args:
|
Args:
|
||||||
text: 输入文本
|
text: 输入文本
|
||||||
Returns:
|
Returns:
|
||||||
Optional[str]: 表情包文件路径,如果没有找到则返回None
|
Optional[str]: 表情包文件路径,如果没有找到则返回None
|
||||||
|
|
||||||
|
|
||||||
可不可以通过 配置文件中的指令 来自定义使用表情包的逻辑?
|
可不可以通过 配置文件中的指令 来自定义使用表情包的逻辑?
|
||||||
我觉得可行
|
我觉得可行
|
||||||
|
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
|
|
@ -121,7 +115,7 @@ class EmojiManager:
|
||||||
|
|
||||||
try:
|
try:
|
||||||
# 获取所有表情包
|
# 获取所有表情包
|
||||||
all_emojis = list(self.db.emoji.find({}, {'_id': 1, 'path': 1, 'embedding': 1, 'description': 1}))
|
all_emojis = list(db.emoji.find({}, {"_id": 1, "path": 1, "embedding": 1, "description": 1}))
|
||||||
|
|
||||||
if not all_emojis:
|
if not all_emojis:
|
||||||
logger.warning("数据库中没有任何表情包")
|
logger.warning("数据库中没有任何表情包")
|
||||||
|
|
@ -140,34 +134,31 @@ class EmojiManager:
|
||||||
|
|
||||||
# 计算所有表情包与输入文本的相似度
|
# 计算所有表情包与输入文本的相似度
|
||||||
emoji_similarities = [
|
emoji_similarities = [
|
||||||
(emoji, cosine_similarity(text_embedding, emoji.get('embedding', [])))
|
(emoji, cosine_similarity(text_embedding, emoji.get("embedding", []))) for emoji in all_emojis
|
||||||
for emoji in all_emojis
|
|
||||||
]
|
]
|
||||||
|
|
||||||
# 按相似度降序排序
|
# 按相似度降序排序
|
||||||
emoji_similarities.sort(key=lambda x: x[1], reverse=True)
|
emoji_similarities.sort(key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
# 获取前3个最相似的表情包
|
# 获取前3个最相似的表情包
|
||||||
top_10_emojis = emoji_similarities[:10 if len(emoji_similarities) > 10 else len(emoji_similarities)]
|
top_10_emojis = emoji_similarities[: 10 if len(emoji_similarities) > 10 else len(emoji_similarities)]
|
||||||
|
|
||||||
if not top_10_emojis:
|
if not top_10_emojis:
|
||||||
logger.warning("未找到匹配的表情包")
|
logger.warning("未找到匹配的表情包")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
# 从前3个中随机选择一个
|
# 从前3个中随机选择一个
|
||||||
selected_emoji, similarity = random.choice(top_10_emojis)
|
selected_emoji, similarity = random.choice(top_10_emojis)
|
||||||
|
|
||||||
if selected_emoji and 'path' in selected_emoji:
|
if selected_emoji and "path" in selected_emoji:
|
||||||
# 更新使用次数
|
# 更新使用次数
|
||||||
self.db.emoji.update_one(
|
db.emoji.update_one({"_id": selected_emoji["_id"]}, {"$inc": {"usage_count": 1}})
|
||||||
{'_id': selected_emoji['_id']},
|
|
||||||
{'$inc': {'usage_count': 1}}
|
|
||||||
)
|
|
||||||
|
|
||||||
logger.success(
|
logger.success(
|
||||||
f"找到匹配的表情包: {selected_emoji.get('description', '无描述')} (相似度: {similarity:.4f})")
|
f"找到匹配的表情包: {selected_emoji.get('description', '无描述')} (相似度: {similarity:.4f})"
|
||||||
|
)
|
||||||
# 稍微改一下文本描述,不然容易产生幻觉,描述已经包含 表情包 了
|
# 稍微改一下文本描述,不然容易产生幻觉,描述已经包含 表情包 了
|
||||||
return selected_emoji['path'], "[ %s ]" % selected_emoji.get('description', '无描述')
|
return selected_emoji["path"], "[ %s ]" % selected_emoji.get("description", "无描述")
|
||||||
|
|
||||||
except Exception as search_error:
|
except Exception as search_error:
|
||||||
logger.error(f"搜索表情包失败: {str(search_error)}")
|
logger.error(f"搜索表情包失败: {str(search_error)}")
|
||||||
|
|
@ -179,7 +170,6 @@ class EmojiManager:
|
||||||
logger.error(f"获取表情包失败: {str(e)}")
|
logger.error(f"获取表情包失败: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
|
|
||||||
async def _get_emoji_discription(self, image_base64: str) -> str:
|
async def _get_emoji_discription(self, image_base64: str) -> str:
|
||||||
"""获取表情包的标签,使用image_manager的描述生成功能"""
|
"""获取表情包的标签,使用image_manager的描述生成功能"""
|
||||||
|
|
||||||
|
|
@ -187,16 +177,16 @@ class EmojiManager:
|
||||||
# 使用image_manager获取描述,去掉前后的方括号和"表情包:"前缀
|
# 使用image_manager获取描述,去掉前后的方括号和"表情包:"前缀
|
||||||
description = await image_manager.get_emoji_description(image_base64)
|
description = await image_manager.get_emoji_description(image_base64)
|
||||||
# 去掉[表情包:xxx]的格式,只保留描述内容
|
# 去掉[表情包:xxx]的格式,只保留描述内容
|
||||||
description = description.strip('[]').replace('表情包:', '')
|
description = description.strip("[]").replace("表情包:", "")
|
||||||
return description
|
return description
|
||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"获取标签失败: {str(e)}")
|
logger.error(f"获取标签失败: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
||||||
async def _check_emoji(self, image_base64: str, image_format: str) -> str:
|
async def _check_emoji(self, image_base64: str, image_format: str) -> str:
|
||||||
try:
|
try:
|
||||||
prompt = f'这是一个表情包,请回答这个表情包是否满足\"{global_config.EMOJI_CHECK_PROMPT}\"的要求,是则回答是,否则回答否,不要出现任何其他内容'
|
prompt = f'这是一个表情包,请回答这个表情包是否满足"{global_config.EMOJI_CHECK_PROMPT}"的要求,是则回答是,否则回答否,不要出现任何其他内容'
|
||||||
|
|
||||||
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64, image_format)
|
content, _ = await self.vlm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
logger.debug(f"输出描述: {content}")
|
logger.debug(f"输出描述: {content}")
|
||||||
|
|
@ -208,9 +198,9 @@ class EmojiManager:
|
||||||
|
|
||||||
async def _get_kimoji_for_text(self, text: str):
|
async def _get_kimoji_for_text(self, text: str):
|
||||||
try:
|
try:
|
||||||
prompt = f'这是{global_config.BOT_NICKNAME}将要发送的消息内容:\n{text}\n若要为其配上表情包,请你输出这个表情包应该表达怎样的情感,应该给人什么样的感觉,不要太简洁也不要太长,注意不要输出任何对消息内容的分析内容,只输出\"一种什么样的感觉\"中间的形容词部分。'
|
prompt = f'这是{global_config.BOT_NICKNAME}将要发送的消息内容:\n{text}\n若要为其配上表情包,请你输出这个表情包应该表达怎样的情感,应该给人什么样的感觉,不要太简洁也不要太长,注意不要输出任何对消息内容的分析内容,只输出"一种什么样的感觉"中间的形容词部分。'
|
||||||
|
|
||||||
content, _ = await self.llm_emotion_judge.generate_response_async(prompt,temperature=1.5)
|
content, _ = await self.llm_emotion_judge.generate_response_async(prompt, temperature=1.5)
|
||||||
logger.info(f"输出描述: {content}")
|
logger.info(f"输出描述: {content}")
|
||||||
return content
|
return content
|
||||||
|
|
||||||
|
|
@ -221,67 +211,62 @@ class EmojiManager:
|
||||||
async def scan_new_emojis(self):
|
async def scan_new_emojis(self):
|
||||||
"""扫描新的表情包"""
|
"""扫描新的表情包"""
|
||||||
try:
|
try:
|
||||||
emoji_dir = "data/emoji"
|
emoji_dir = self.EMOJI_DIR
|
||||||
os.makedirs(emoji_dir, exist_ok=True)
|
os.makedirs(emoji_dir, exist_ok=True)
|
||||||
|
|
||||||
# 获取所有支持的图片文件
|
# 获取所有支持的图片文件
|
||||||
files_to_process = [f for f in os.listdir(emoji_dir) if
|
files_to_process = [
|
||||||
f.lower().endswith(('.jpg', '.jpeg', '.png', '.gif'))]
|
f for f in os.listdir(emoji_dir) if f.lower().endswith((".jpg", ".jpeg", ".png", ".gif"))
|
||||||
|
]
|
||||||
|
|
||||||
for filename in files_to_process:
|
for filename in files_to_process:
|
||||||
image_path = os.path.join(emoji_dir, filename)
|
image_path = os.path.join(emoji_dir, filename)
|
||||||
|
|
||||||
# 获取图片的base64编码和哈希值
|
# 获取图片的base64编码和哈希值
|
||||||
image_base64 = image_path_to_base64(image_path)
|
image_base64 = image_path_to_base64(image_path)
|
||||||
if image_base64 is None:
|
if image_base64 is None:
|
||||||
os.remove(image_path)
|
os.remove(image_path)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
image_bytes = base64.b64decode(image_base64)
|
image_bytes = base64.b64decode(image_base64)
|
||||||
image_hash = hashlib.md5(image_bytes).hexdigest()
|
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||||
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
# 检查是否已经注册过
|
# 检查是否已经注册过
|
||||||
existing_emoji = self.db['emoji'].find_one({'filename': filename})
|
existing_emoji = db["emoji"].find_one({"hash": image_hash})
|
||||||
description = None
|
description = None
|
||||||
|
|
||||||
if existing_emoji:
|
if existing_emoji:
|
||||||
# 即使表情包已存在,也检查是否需要同步到images集合
|
# 即使表情包已存在,也检查是否需要同步到images集合
|
||||||
description = existing_emoji.get('discription')
|
description = existing_emoji.get("discription")
|
||||||
# 检查是否在images集合中存在
|
# 检查是否在images集合中存在
|
||||||
existing_image = image_manager.db.images.find_one({'hash': image_hash})
|
existing_image = db.images.find_one({"hash": image_hash})
|
||||||
if not existing_image:
|
if not existing_image:
|
||||||
# 同步到images集合
|
# 同步到images集合
|
||||||
image_doc = {
|
image_doc = {
|
||||||
'hash': image_hash,
|
"hash": image_hash,
|
||||||
'path': image_path,
|
"path": image_path,
|
||||||
'type': 'emoji',
|
"type": "emoji",
|
||||||
'description': description,
|
"description": description,
|
||||||
'timestamp': int(time.time())
|
"timestamp": int(time.time()),
|
||||||
}
|
}
|
||||||
image_manager.db.images.update_one(
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
{'hash': image_hash},
|
|
||||||
{'$set': image_doc},
|
|
||||||
upsert=True
|
|
||||||
)
|
|
||||||
# 保存描述到image_descriptions集合
|
# 保存描述到image_descriptions集合
|
||||||
image_manager._save_description_to_db(image_hash, description, 'emoji')
|
image_manager._save_description_to_db(image_hash, description, "emoji")
|
||||||
logger.success(f"同步已存在的表情包到images集合: {filename}")
|
logger.success(f"同步已存在的表情包到images集合: {filename}")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 检查是否在images集合中已有描述
|
# 检查是否在images集合中已有描述
|
||||||
existing_description = image_manager._get_description_from_db(image_hash, 'emoji')
|
existing_description = image_manager._get_description_from_db(image_hash, "emoji")
|
||||||
|
|
||||||
if existing_description:
|
if existing_description:
|
||||||
description = existing_description
|
description = existing_description
|
||||||
else:
|
else:
|
||||||
# 获取表情包的描述
|
# 获取表情包的描述
|
||||||
description = await self._get_emoji_discription(image_base64)
|
description = await self._get_emoji_discription(image_base64)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
if global_config.EMOJI_CHECK:
|
if global_config.EMOJI_CHECK:
|
||||||
check = await self._check_emoji(image_base64, image_format)
|
check = await self._check_emoji(image_base64, image_format)
|
||||||
if '是' not in check:
|
if "是" not in check:
|
||||||
os.remove(image_path)
|
os.remove(image_path)
|
||||||
logger.info(f"描述: {description}")
|
logger.info(f"描述: {description}")
|
||||||
|
|
||||||
|
|
@ -289,44 +274,39 @@ class EmojiManager:
|
||||||
logger.info(f"其不满足过滤规则,被剔除 {check}")
|
logger.info(f"其不满足过滤规则,被剔除 {check}")
|
||||||
continue
|
continue
|
||||||
logger.info(f"check通过 {check}")
|
logger.info(f"check通过 {check}")
|
||||||
|
|
||||||
if description is not None:
|
if description is not None:
|
||||||
embedding = await get_embedding(description)
|
embedding = await get_embedding(description)
|
||||||
|
|
||||||
if description is not None:
|
if description is not None:
|
||||||
embedding = await get_embedding(description)
|
embedding = await get_embedding(description)
|
||||||
|
|
||||||
# 准备数据库记录
|
# 准备数据库记录
|
||||||
emoji_record = {
|
emoji_record = {
|
||||||
'filename': filename,
|
"filename": filename,
|
||||||
'path': image_path,
|
"path": image_path,
|
||||||
'embedding': embedding,
|
"embedding": embedding,
|
||||||
'discription': description,
|
"discription": description,
|
||||||
'hash': image_hash,
|
"hash": image_hash,
|
||||||
'timestamp': int(time.time())
|
"timestamp": int(time.time()),
|
||||||
}
|
}
|
||||||
|
|
||||||
# 保存到emoji数据库
|
# 保存到emoji数据库
|
||||||
self.db['emoji'].insert_one(emoji_record)
|
db["emoji"].insert_one(emoji_record)
|
||||||
logger.success(f"注册新表情包: {filename}")
|
logger.success(f"注册新表情包: {filename}")
|
||||||
logger.info(f"描述: {description}")
|
logger.info(f"描述: {description}")
|
||||||
|
|
||||||
|
|
||||||
# 保存到images数据库
|
# 保存到images数据库
|
||||||
image_doc = {
|
image_doc = {
|
||||||
'hash': image_hash,
|
"hash": image_hash,
|
||||||
'path': image_path,
|
"path": image_path,
|
||||||
'type': 'emoji',
|
"type": "emoji",
|
||||||
'description': description,
|
"description": description,
|
||||||
'timestamp': int(time.time())
|
"timestamp": int(time.time()),
|
||||||
}
|
}
|
||||||
image_manager.db.images.update_one(
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
{'hash': image_hash},
|
|
||||||
{'$set': image_doc},
|
|
||||||
upsert=True
|
|
||||||
)
|
|
||||||
# 保存描述到image_descriptions集合
|
# 保存描述到image_descriptions集合
|
||||||
image_manager._save_description_to_db(image_hash, description, 'emoji')
|
image_manager._save_description_to_db(image_hash, description, "emoji")
|
||||||
logger.success(f"同步保存到images集合: {filename}")
|
logger.success(f"同步保存到images集合: {filename}")
|
||||||
else:
|
else:
|
||||||
logger.warning(f"跳过表情包: {filename}")
|
logger.warning(f"跳过表情包: {filename}")
|
||||||
|
|
@ -348,40 +328,47 @@ class EmojiManager:
|
||||||
try:
|
try:
|
||||||
self._ensure_db()
|
self._ensure_db()
|
||||||
# 获取所有表情包记录
|
# 获取所有表情包记录
|
||||||
all_emojis = list(self.db.emoji.find())
|
all_emojis = list(db.emoji.find())
|
||||||
removed_count = 0
|
removed_count = 0
|
||||||
total_count = len(all_emojis)
|
total_count = len(all_emojis)
|
||||||
|
|
||||||
for emoji in all_emojis:
|
for emoji in all_emojis:
|
||||||
try:
|
try:
|
||||||
if 'path' not in emoji:
|
if "path" not in emoji:
|
||||||
logger.warning(f"发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
|
logger.warning(f"发现无效记录(缺少path字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
self.db.emoji.delete_one({'_id': emoji['_id']})
|
db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if 'embedding' not in emoji:
|
if "embedding" not in emoji:
|
||||||
logger.warning(f"发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
|
logger.warning(f"发现过时记录(缺少embedding字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
self.db.emoji.delete_one({'_id': emoji['_id']})
|
db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 检查文件是否存在
|
# 检查文件是否存在
|
||||||
if not os.path.exists(emoji['path']):
|
if not os.path.exists(emoji["path"]):
|
||||||
logger.warning(f"表情包文件已被删除: {emoji['path']}")
|
logger.warning(f"表情包文件已被删除: {emoji['path']}")
|
||||||
# 从数据库中删除记录
|
# 从数据库中删除记录
|
||||||
result = self.db.emoji.delete_one({'_id': emoji['_id']})
|
result = db.emoji.delete_one({"_id": emoji["_id"]})
|
||||||
if result.deleted_count > 0:
|
if result.deleted_count > 0:
|
||||||
logger.debug(f"成功删除数据库记录: {emoji['_id']}")
|
logger.debug(f"成功删除数据库记录: {emoji['_id']}")
|
||||||
removed_count += 1
|
removed_count += 1
|
||||||
else:
|
else:
|
||||||
logger.error(f"删除数据库记录失败: {emoji['_id']}")
|
logger.error(f"删除数据库记录失败: {emoji['_id']}")
|
||||||
|
continue
|
||||||
|
|
||||||
|
if "hash" not in emoji:
|
||||||
|
logger.warning(f"发现缺失记录(缺少hash字段),ID: {emoji.get('_id', 'unknown')}")
|
||||||
|
hash = hashlib.md5(open(emoji["path"], "rb").read()).hexdigest()
|
||||||
|
db.emoji.update_one({"_id": emoji["_id"]}, {"$set": {"hash": hash}})
|
||||||
|
|
||||||
except Exception as item_error:
|
except Exception as item_error:
|
||||||
logger.error(f"处理表情包记录时出错: {str(item_error)}")
|
logger.error(f"处理表情包记录时出错: {str(item_error)}")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
# 验证清理结果
|
# 验证清理结果
|
||||||
remaining_count = self.db.emoji.count_documents({})
|
remaining_count = db.emoji.count_documents({})
|
||||||
if removed_count > 0:
|
if removed_count > 0:
|
||||||
logger.success(f"已清理 {removed_count} 个失效的表情包记录")
|
logger.success(f"已清理 {removed_count} 个失效的表情包记录")
|
||||||
logger.info(f"清理前总数: {total_count} | 清理后总数: {remaining_count}")
|
logger.info(f"清理前总数: {total_count} | 清理后总数: {remaining_count}")
|
||||||
|
|
@ -401,5 +388,3 @@ class EmojiManager:
|
||||||
# 创建全局单例
|
# 创建全局单例
|
||||||
|
|
||||||
emoji_manager = EmojiManager()
|
emoji_manager = EmojiManager()
|
||||||
|
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -5,7 +5,7 @@ from typing import List, Optional, Tuple, Union
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
from .config import global_config
|
from .config import global_config
|
||||||
from .message import MessageRecv, MessageThinking, Message
|
from .message import MessageRecv, MessageThinking, Message
|
||||||
|
|
@ -34,7 +34,6 @@ class ResponseGenerator:
|
||||||
self.model_v25 = LLM_request(
|
self.model_v25 = LLM_request(
|
||||||
model=global_config.llm_normal_minor, temperature=0.7, max_tokens=1000
|
model=global_config.llm_normal_minor, temperature=0.7, max_tokens=1000
|
||||||
)
|
)
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.current_model_type = "r1" # 默认使用 R1
|
self.current_model_type = "r1" # 默认使用 R1
|
||||||
|
|
||||||
async def generate_response(
|
async def generate_response(
|
||||||
|
|
@ -154,7 +153,7 @@ class ResponseGenerator:
|
||||||
reasoning_content: str,
|
reasoning_content: str,
|
||||||
):
|
):
|
||||||
"""保存对话记录到数据库"""
|
"""保存对话记录到数据库"""
|
||||||
self.db.reasoning_logs.insert_one(
|
db.reasoning_logs.insert_one(
|
||||||
{
|
{
|
||||||
"time": time.time(),
|
"time": time.time(),
|
||||||
"chat_id": message.chat_stream.stream_id,
|
"chat_id": message.chat_stream.stream_id,
|
||||||
|
|
@ -211,7 +210,6 @@ class ResponseGenerator:
|
||||||
|
|
||||||
class InitiativeMessageGenerate:
|
class InitiativeMessageGenerate:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.model_r1 = LLM_request(model=global_config.llm_reasoning, temperature=0.7)
|
self.model_r1 = LLM_request(model=global_config.llm_reasoning, temperature=0.7)
|
||||||
self.model_v3 = LLM_request(model=global_config.llm_normal, temperature=0.7)
|
self.model_v3 = LLM_request(model=global_config.llm_normal, temperature=0.7)
|
||||||
self.model_r1_distill = LLM_request(
|
self.model_r1_distill = LLM_request(
|
||||||
|
|
|
||||||
|
|
@ -23,8 +23,8 @@ urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class Message(MessageBase):
|
class Message(MessageBase):
|
||||||
chat_stream: ChatStream=None
|
chat_stream: ChatStream = None
|
||||||
reply: Optional['Message'] = None
|
reply: Optional["Message"] = None
|
||||||
detailed_plain_text: str = ""
|
detailed_plain_text: str = ""
|
||||||
processed_plain_text: str = ""
|
processed_plain_text: str = ""
|
||||||
|
|
||||||
|
|
@ -35,7 +35,7 @@ class Message(MessageBase):
|
||||||
chat_stream: ChatStream,
|
chat_stream: ChatStream,
|
||||||
user_info: UserInfo,
|
user_info: UserInfo,
|
||||||
message_segment: Optional[Seg] = None,
|
message_segment: Optional[Seg] = None,
|
||||||
reply: Optional['MessageRecv'] = None,
|
reply: Optional["MessageRecv"] = None,
|
||||||
detailed_plain_text: str = "",
|
detailed_plain_text: str = "",
|
||||||
processed_plain_text: str = "",
|
processed_plain_text: str = "",
|
||||||
):
|
):
|
||||||
|
|
@ -45,21 +45,17 @@ class Message(MessageBase):
|
||||||
message_id=message_id,
|
message_id=message_id,
|
||||||
time=time,
|
time=time,
|
||||||
group_info=chat_stream.group_info,
|
group_info=chat_stream.group_info,
|
||||||
user_info=user_info
|
user_info=user_info,
|
||||||
)
|
)
|
||||||
|
|
||||||
# 调用父类初始化
|
# 调用父类初始化
|
||||||
super().__init__(
|
super().__init__(message_info=message_info, message_segment=message_segment, raw_message=None)
|
||||||
message_info=message_info,
|
|
||||||
message_segment=message_segment,
|
|
||||||
raw_message=None
|
|
||||||
)
|
|
||||||
|
|
||||||
self.chat_stream = chat_stream
|
self.chat_stream = chat_stream
|
||||||
# 文本处理相关属性
|
# 文本处理相关属性
|
||||||
self.processed_plain_text = processed_plain_text
|
self.processed_plain_text = processed_plain_text
|
||||||
self.detailed_plain_text = detailed_plain_text
|
self.detailed_plain_text = detailed_plain_text
|
||||||
|
|
||||||
# 回复消息
|
# 回复消息
|
||||||
self.reply = reply
|
self.reply = reply
|
||||||
|
|
||||||
|
|
@ -74,41 +70,38 @@ class MessageRecv(Message):
|
||||||
Args:
|
Args:
|
||||||
message_dict: MessageCQ序列化后的字典
|
message_dict: MessageCQ序列化后的字典
|
||||||
"""
|
"""
|
||||||
self.message_info = BaseMessageInfo.from_dict(message_dict.get('message_info', {}))
|
self.message_info = BaseMessageInfo.from_dict(message_dict.get("message_info", {}))
|
||||||
|
|
||||||
message_segment = message_dict.get('message_segment', {})
|
message_segment = message_dict.get("message_segment", {})
|
||||||
|
|
||||||
if message_segment.get('data','') == '[json]':
|
if message_segment.get("data", "") == "[json]":
|
||||||
# 提取json消息中的展示信息
|
# 提取json消息中的展示信息
|
||||||
pattern = r'\[CQ:json,data=(?P<json_data>.+?)\]'
|
pattern = r"\[CQ:json,data=(?P<json_data>.+?)\]"
|
||||||
match = re.search(pattern, message_dict.get('raw_message',''))
|
match = re.search(pattern, message_dict.get("raw_message", ""))
|
||||||
raw_json = html.unescape(match.group('json_data'))
|
raw_json = html.unescape(match.group("json_data"))
|
||||||
try:
|
try:
|
||||||
json_message = json.loads(raw_json)
|
json_message = json.loads(raw_json)
|
||||||
except json.JSONDecodeError:
|
except json.JSONDecodeError:
|
||||||
json_message = {}
|
json_message = {}
|
||||||
message_segment['data'] = json_message.get('prompt','')
|
message_segment["data"] = json_message.get("prompt", "")
|
||||||
|
|
||||||
|
self.message_segment = Seg.from_dict(message_dict.get("message_segment", {}))
|
||||||
|
self.raw_message = message_dict.get("raw_message")
|
||||||
|
|
||||||
self.message_segment = Seg.from_dict(message_dict.get('message_segment', {}))
|
|
||||||
self.raw_message = message_dict.get('raw_message')
|
|
||||||
|
|
||||||
# 处理消息内容
|
# 处理消息内容
|
||||||
self.processed_plain_text = "" # 初始化为空字符串
|
self.processed_plain_text = "" # 初始化为空字符串
|
||||||
self.detailed_plain_text = "" # 初始化为空字符串
|
self.detailed_plain_text = "" # 初始化为空字符串
|
||||||
self.is_emoji=False
|
self.is_emoji = False
|
||||||
|
|
||||||
|
def update_chat_stream(self, chat_stream: ChatStream):
|
||||||
def update_chat_stream(self,chat_stream:ChatStream):
|
self.chat_stream = chat_stream
|
||||||
self.chat_stream=chat_stream
|
|
||||||
|
|
||||||
async def process(self) -> None:
|
async def process(self) -> None:
|
||||||
"""处理消息内容,生成纯文本和详细文本
|
"""处理消息内容,生成纯文本和详细文本
|
||||||
|
|
||||||
这个方法必须在创建实例后显式调用,因为它包含异步操作。
|
这个方法必须在创建实例后显式调用,因为它包含异步操作。
|
||||||
"""
|
"""
|
||||||
self.processed_plain_text = await self._process_message_segments(
|
self.processed_plain_text = await self._process_message_segments(self.message_segment)
|
||||||
self.message_segment
|
|
||||||
)
|
|
||||||
self.detailed_plain_text = self._generate_detailed_text()
|
self.detailed_plain_text = self._generate_detailed_text()
|
||||||
|
|
||||||
async def _process_message_segments(self, segment: Seg) -> str:
|
async def _process_message_segments(self, segment: Seg) -> str:
|
||||||
|
|
@ -157,16 +150,12 @@ class MessageRecv(Message):
|
||||||
else:
|
else:
|
||||||
return f"[{seg.type}:{str(seg.data)}]"
|
return f"[{seg.type}:{str(seg.data)}]"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(
|
logger.error(f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}")
|
||||||
f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}"
|
|
||||||
)
|
|
||||||
return f"[处理失败的{seg.type}消息]"
|
return f"[处理失败的{seg.type}消息]"
|
||||||
|
|
||||||
def _generate_detailed_text(self) -> str:
|
def _generate_detailed_text(self) -> str:
|
||||||
"""生成详细文本,包含时间和用户信息"""
|
"""生成详细文本,包含时间和用户信息"""
|
||||||
time_str = time.strftime(
|
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(self.message_info.time))
|
||||||
"%m-%d %H:%M:%S", time.localtime(self.message_info.time)
|
|
||||||
)
|
|
||||||
user_info = self.message_info.user_info
|
user_info = self.message_info.user_info
|
||||||
name = (
|
name = (
|
||||||
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
||||||
|
|
@ -174,7 +163,7 @@ class MessageRecv(Message):
|
||||||
else f"{user_info.user_nickname}(ta的id:{user_info.user_id})"
|
else f"{user_info.user_nickname}(ta的id:{user_info.user_id})"
|
||||||
)
|
)
|
||||||
return f"[{time_str}] {name}: {self.processed_plain_text}\n"
|
return f"[{time_str}] {name}: {self.processed_plain_text}\n"
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class MessageProcessBase(Message):
|
class MessageProcessBase(Message):
|
||||||
|
|
@ -257,16 +246,12 @@ class MessageProcessBase(Message):
|
||||||
else:
|
else:
|
||||||
return f"[{seg.type}:{str(seg.data)}]"
|
return f"[{seg.type}:{str(seg.data)}]"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(
|
logger.error(f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}")
|
||||||
f"处理消息段失败: {str(e)}, 类型: {seg.type}, 数据: {seg.data}"
|
|
||||||
)
|
|
||||||
return f"[处理失败的{seg.type}消息]"
|
return f"[处理失败的{seg.type}消息]"
|
||||||
|
|
||||||
def _generate_detailed_text(self) -> str:
|
def _generate_detailed_text(self) -> str:
|
||||||
"""生成详细文本,包含时间和用户信息"""
|
"""生成详细文本,包含时间和用户信息"""
|
||||||
time_str = time.strftime(
|
time_str = time.strftime("%m-%d %H:%M:%S", time.localtime(self.message_info.time))
|
||||||
"%m-%d %H:%M:%S", time.localtime(self.message_info.time)
|
|
||||||
)
|
|
||||||
user_info = self.message_info.user_info
|
user_info = self.message_info.user_info
|
||||||
name = (
|
name = (
|
||||||
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
f"{user_info.user_nickname}(ta的昵称:{user_info.user_cardname},ta的id:{user_info.user_id})"
|
||||||
|
|
@ -330,10 +315,11 @@ class MessageSending(MessageProcessBase):
|
||||||
self.is_head = is_head
|
self.is_head = is_head
|
||||||
self.is_emoji = is_emoji
|
self.is_emoji = is_emoji
|
||||||
|
|
||||||
def set_reply(self, reply: Optional["MessageRecv"]) -> None:
|
def set_reply(self, reply: Optional["MessageRecv"] = None) -> None:
|
||||||
"""设置回复消息"""
|
"""设置回复消息"""
|
||||||
if reply:
|
if reply:
|
||||||
self.reply = reply
|
self.reply = reply
|
||||||
|
if self.reply:
|
||||||
self.reply_to_message_id = self.reply.message_info.message_id
|
self.reply_to_message_id = self.reply.message_info.message_id
|
||||||
self.message_segment = Seg(
|
self.message_segment = Seg(
|
||||||
type="seglist",
|
type="seglist",
|
||||||
|
|
@ -346,9 +332,7 @@ class MessageSending(MessageProcessBase):
|
||||||
async def process(self) -> None:
|
async def process(self) -> None:
|
||||||
"""处理消息内容,生成纯文本和详细文本"""
|
"""处理消息内容,生成纯文本和详细文本"""
|
||||||
if self.message_segment:
|
if self.message_segment:
|
||||||
self.processed_plain_text = await self._process_message_segments(
|
self.processed_plain_text = await self._process_message_segments(self.message_segment)
|
||||||
self.message_segment
|
|
||||||
)
|
|
||||||
self.detailed_plain_text = self._generate_detailed_text()
|
self.detailed_plain_text = self._generate_detailed_text()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
|
|
@ -377,10 +361,7 @@ class MessageSending(MessageProcessBase):
|
||||||
|
|
||||||
def is_private_message(self) -> bool:
|
def is_private_message(self) -> bool:
|
||||||
"""判断是否为私聊消息"""
|
"""判断是否为私聊消息"""
|
||||||
return (
|
return self.message_info.group_info is None or self.message_info.group_info.group_id is None
|
||||||
self.message_info.group_info is None
|
|
||||||
or self.message_info.group_info.group_id is None
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
|
|
|
||||||
|
|
@ -65,6 +65,8 @@ class GroupInfo:
|
||||||
Returns:
|
Returns:
|
||||||
GroupInfo: 新的实例
|
GroupInfo: 新的实例
|
||||||
"""
|
"""
|
||||||
|
if data.get('group_id') is None:
|
||||||
|
return None
|
||||||
return cls(
|
return cls(
|
||||||
platform=data.get('platform'),
|
platform=data.get('platform'),
|
||||||
group_id=data.get('group_id'),
|
group_id=data.get('group_id'),
|
||||||
|
|
@ -129,8 +131,8 @@ class BaseMessageInfo:
|
||||||
Returns:
|
Returns:
|
||||||
BaseMessageInfo: 新的实例
|
BaseMessageInfo: 新的实例
|
||||||
"""
|
"""
|
||||||
group_info = GroupInfo(**data.get('group_info', {}))
|
group_info = GroupInfo.from_dict(data.get('group_info', {}))
|
||||||
user_info = UserInfo(**data.get('user_info', {}))
|
user_info = UserInfo.from_dict(data.get('user_info', {}))
|
||||||
return cls(
|
return cls(
|
||||||
platform=data.get('platform'),
|
platform=data.get('platform'),
|
||||||
message_id=data.get('message_id'),
|
message_id=data.get('message_id'),
|
||||||
|
|
@ -173,7 +175,7 @@ class MessageBase:
|
||||||
Returns:
|
Returns:
|
||||||
MessageBase: 新的实例
|
MessageBase: 新的实例
|
||||||
"""
|
"""
|
||||||
message_info = BaseMessageInfo(**data.get('message_info', {}))
|
message_info = BaseMessageInfo.from_dict(data.get('message_info', {}))
|
||||||
message_segment = Seg(**data.get('message_segment', {}))
|
message_segment = Seg(**data.get('message_segment', {}))
|
||||||
raw_message = data.get('raw_message',None)
|
raw_message = data.get('raw_message',None)
|
||||||
return cls(
|
return cls(
|
||||||
|
|
|
||||||
|
|
@ -8,48 +8,40 @@ from .cq_code import cq_code_tool
|
||||||
from .utils_cq import parse_cq_code
|
from .utils_cq import parse_cq_code
|
||||||
from .utils_user import get_groupname
|
from .utils_user import get_groupname
|
||||||
from .message_base import Seg, GroupInfo, UserInfo, BaseMessageInfo, MessageBase
|
from .message_base import Seg, GroupInfo, UserInfo, BaseMessageInfo, MessageBase
|
||||||
|
|
||||||
# 禁用SSL警告
|
# 禁用SSL警告
|
||||||
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
|
||||||
|
|
||||||
#这个类是消息数据类,用于存储和管理消息数据。
|
# 这个类是消息数据类,用于存储和管理消息数据。
|
||||||
#它定义了消息的属性,包括群组ID、用户ID、消息ID、原始消息内容、纯文本内容和时间戳。
|
# 它定义了消息的属性,包括群组ID、用户ID、消息ID、原始消息内容、纯文本内容和时间戳。
|
||||||
#它还定义了两个辅助属性:keywords用于提取消息的关键词,is_plain_text用于判断消息是否为纯文本。
|
# 它还定义了两个辅助属性:keywords用于提取消息的关键词,is_plain_text用于判断消息是否为纯文本。
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class MessageCQ(MessageBase):
|
class MessageCQ(MessageBase):
|
||||||
"""QQ消息基类,继承自MessageBase
|
"""QQ消息基类,继承自MessageBase
|
||||||
|
|
||||||
最小必要参数:
|
最小必要参数:
|
||||||
- message_id: 消息ID
|
- message_id: 消息ID
|
||||||
- user_id: 发送者/接收者ID
|
- user_id: 发送者/接收者ID
|
||||||
- platform: 平台标识(默认为"qq")
|
- platform: 平台标识(默认为"qq")
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self, message_id: int, user_info: UserInfo, group_info: Optional[GroupInfo] = None, platform: str = "qq"
|
||||||
message_id: int,
|
|
||||||
user_info: UserInfo,
|
|
||||||
group_info: Optional[GroupInfo] = None,
|
|
||||||
platform: str = "qq"
|
|
||||||
):
|
):
|
||||||
# 构造基础消息信息
|
# 构造基础消息信息
|
||||||
message_info = BaseMessageInfo(
|
message_info = BaseMessageInfo(
|
||||||
platform=platform,
|
platform=platform, message_id=message_id, time=int(time.time()), group_info=group_info, user_info=user_info
|
||||||
message_id=message_id,
|
|
||||||
time=int(time.time()),
|
|
||||||
group_info=group_info,
|
|
||||||
user_info=user_info
|
|
||||||
)
|
)
|
||||||
# 调用父类初始化,message_segment 由子类设置
|
# 调用父类初始化,message_segment 由子类设置
|
||||||
super().__init__(
|
super().__init__(message_info=message_info, message_segment=None, raw_message=None)
|
||||||
message_info=message_info,
|
|
||||||
message_segment=None,
|
|
||||||
raw_message=None
|
|
||||||
)
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class MessageRecvCQ(MessageCQ):
|
class MessageRecvCQ(MessageCQ):
|
||||||
"""QQ接收消息类,用于解析raw_message到Seg对象"""
|
"""QQ接收消息类,用于解析raw_message到Seg对象"""
|
||||||
|
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
message_id: int,
|
message_id: int,
|
||||||
|
|
@ -61,14 +53,14 @@ class MessageRecvCQ(MessageCQ):
|
||||||
):
|
):
|
||||||
# 调用父类初始化
|
# 调用父类初始化
|
||||||
super().__init__(message_id, user_info, group_info, platform)
|
super().__init__(message_id, user_info, group_info, platform)
|
||||||
|
|
||||||
# 私聊消息不携带group_info
|
# 私聊消息不携带group_info
|
||||||
if group_info is None:
|
if group_info is None:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
elif group_info.group_name is None:
|
elif group_info.group_name is None:
|
||||||
group_info.group_name = get_groupname(group_info.group_id)
|
group_info.group_name = get_groupname(group_info.group_id)
|
||||||
|
|
||||||
# 解析消息段
|
# 解析消息段
|
||||||
self.message_segment = self._parse_message(raw_message, reply_message)
|
self.message_segment = self._parse_message(raw_message, reply_message)
|
||||||
self.raw_message = raw_message
|
self.raw_message = raw_message
|
||||||
|
|
@ -77,10 +69,10 @@ class MessageRecvCQ(MessageCQ):
|
||||||
"""解析消息内容为Seg对象"""
|
"""解析消息内容为Seg对象"""
|
||||||
cq_code_dict_list = []
|
cq_code_dict_list = []
|
||||||
segments = []
|
segments = []
|
||||||
|
|
||||||
start = 0
|
start = 0
|
||||||
while True:
|
while True:
|
||||||
cq_start = message.find('[CQ:', start)
|
cq_start = message.find("[CQ:", start)
|
||||||
if cq_start == -1:
|
if cq_start == -1:
|
||||||
if start < len(message):
|
if start < len(message):
|
||||||
text = message[start:].strip()
|
text = message[start:].strip()
|
||||||
|
|
@ -93,81 +85,80 @@ class MessageRecvCQ(MessageCQ):
|
||||||
if text:
|
if text:
|
||||||
cq_code_dict_list.append(parse_cq_code(text))
|
cq_code_dict_list.append(parse_cq_code(text))
|
||||||
|
|
||||||
cq_end = message.find(']', cq_start)
|
cq_end = message.find("]", cq_start)
|
||||||
if cq_end == -1:
|
if cq_end == -1:
|
||||||
text = message[cq_start:].strip()
|
text = message[cq_start:].strip()
|
||||||
if text:
|
if text:
|
||||||
cq_code_dict_list.append(parse_cq_code(text))
|
cq_code_dict_list.append(parse_cq_code(text))
|
||||||
break
|
break
|
||||||
|
|
||||||
cq_code = message[cq_start:cq_end + 1]
|
cq_code = message[cq_start : cq_end + 1]
|
||||||
cq_code_dict_list.append(parse_cq_code(cq_code))
|
cq_code_dict_list.append(parse_cq_code(cq_code))
|
||||||
start = cq_end + 1
|
start = cq_end + 1
|
||||||
|
|
||||||
# 转换CQ码为Seg对象
|
# 转换CQ码为Seg对象
|
||||||
for code_item in cq_code_dict_list:
|
for code_item in cq_code_dict_list:
|
||||||
message_obj = cq_code_tool.cq_from_dict_to_class(code_item,msg=self,reply=reply_message)
|
message_obj = cq_code_tool.cq_from_dict_to_class(code_item, msg=self, reply=reply_message)
|
||||||
if message_obj.translated_segments:
|
if message_obj.translated_segments:
|
||||||
segments.append(message_obj.translated_segments)
|
segments.append(message_obj.translated_segments)
|
||||||
|
|
||||||
# 如果只有一个segment,直接返回
|
# 如果只有一个segment,直接返回
|
||||||
if len(segments) == 1:
|
if len(segments) == 1:
|
||||||
return segments[0]
|
return segments[0]
|
||||||
|
|
||||||
# 否则返回seglist类型的Seg
|
# 否则返回seglist类型的Seg
|
||||||
return Seg(type='seglist', data=segments)
|
return Seg(type="seglist", data=segments)
|
||||||
|
|
||||||
def to_dict(self) -> Dict:
|
def to_dict(self) -> Dict:
|
||||||
"""转换为字典格式,包含所有必要信息"""
|
"""转换为字典格式,包含所有必要信息"""
|
||||||
base_dict = super().to_dict()
|
base_dict = super().to_dict()
|
||||||
return base_dict
|
return base_dict
|
||||||
|
|
||||||
|
|
||||||
@dataclass
|
@dataclass
|
||||||
class MessageSendCQ(MessageCQ):
|
class MessageSendCQ(MessageCQ):
|
||||||
"""QQ发送消息类,用于将Seg对象转换为raw_message"""
|
"""QQ发送消息类,用于将Seg对象转换为raw_message"""
|
||||||
|
|
||||||
def __init__(
|
def __init__(self, data: Dict):
|
||||||
self,
|
|
||||||
data: Dict
|
|
||||||
):
|
|
||||||
# 调用父类初始化
|
# 调用父类初始化
|
||||||
message_info = BaseMessageInfo.from_dict(data.get('message_info', {}))
|
message_info = BaseMessageInfo.from_dict(data.get("message_info", {}))
|
||||||
message_segment = Seg.from_dict(data.get('message_segment', {}))
|
message_segment = Seg.from_dict(data.get("message_segment", {}))
|
||||||
super().__init__(
|
super().__init__(
|
||||||
message_info.message_id,
|
message_info.message_id,
|
||||||
message_info.user_info,
|
message_info.user_info,
|
||||||
message_info.group_info if message_info.group_info else None,
|
message_info.group_info if message_info.group_info else None,
|
||||||
message_info.platform
|
message_info.platform,
|
||||||
)
|
)
|
||||||
|
|
||||||
self.message_segment = message_segment
|
self.message_segment = message_segment
|
||||||
self.raw_message = self._generate_raw_message()
|
self.raw_message = self._generate_raw_message()
|
||||||
|
|
||||||
def _generate_raw_message(self, ) -> str:
|
def _generate_raw_message(
|
||||||
|
self,
|
||||||
|
) -> str:
|
||||||
"""将Seg对象转换为raw_message"""
|
"""将Seg对象转换为raw_message"""
|
||||||
segments = []
|
segments = []
|
||||||
|
|
||||||
# 处理消息段
|
# 处理消息段
|
||||||
if self.message_segment.type == 'seglist':
|
if self.message_segment.type == "seglist":
|
||||||
for seg in self.message_segment.data:
|
for seg in self.message_segment.data:
|
||||||
segments.append(self._seg_to_cq_code(seg))
|
segments.append(self._seg_to_cq_code(seg))
|
||||||
else:
|
else:
|
||||||
segments.append(self._seg_to_cq_code(self.message_segment))
|
segments.append(self._seg_to_cq_code(self.message_segment))
|
||||||
|
|
||||||
return ''.join(segments)
|
return "".join(segments)
|
||||||
|
|
||||||
def _seg_to_cq_code(self, seg: Seg) -> str:
|
def _seg_to_cq_code(self, seg: Seg) -> str:
|
||||||
"""将单个Seg对象转换为CQ码字符串"""
|
"""将单个Seg对象转换为CQ码字符串"""
|
||||||
if seg.type == 'text':
|
if seg.type == "text":
|
||||||
return str(seg.data)
|
return str(seg.data)
|
||||||
elif seg.type == 'image':
|
elif seg.type == "image":
|
||||||
return cq_code_tool.create_image_cq_base64(seg.data)
|
return cq_code_tool.create_image_cq_base64(seg.data)
|
||||||
elif seg.type == 'emoji':
|
elif seg.type == "emoji":
|
||||||
return cq_code_tool.create_emoji_cq_base64(seg.data)
|
return cq_code_tool.create_emoji_cq_base64(seg.data)
|
||||||
elif seg.type == 'at':
|
elif seg.type == "at":
|
||||||
return f"[CQ:at,qq={seg.data}]"
|
return f"[CQ:at,qq={seg.data}]"
|
||||||
elif seg.type == 'reply':
|
elif seg.type == "reply":
|
||||||
return cq_code_tool.create_reply_cq(int(seg.data))
|
return cq_code_tool.create_reply_cq(int(seg.data))
|
||||||
else:
|
else:
|
||||||
return f"[{seg.data}]"
|
return f"[{seg.data}]"
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -3,7 +3,7 @@ import time
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..memory_system.memory import hippocampus, memory_graph
|
from ..memory_system.memory import hippocampus, memory_graph
|
||||||
from ..moods.moods import MoodManager
|
from ..moods.moods import MoodManager
|
||||||
from ..schedule.schedule_generator import bot_schedule
|
from ..schedule.schedule_generator import bot_schedule
|
||||||
|
|
@ -16,7 +16,6 @@ class PromptBuilder:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.prompt_built = ''
|
self.prompt_built = ''
|
||||||
self.activate_messages = ''
|
self.activate_messages = ''
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -76,7 +75,7 @@ class PromptBuilder:
|
||||||
chat_in_group=True
|
chat_in_group=True
|
||||||
chat_talking_prompt = ''
|
chat_talking_prompt = ''
|
||||||
if stream_id:
|
if stream_id:
|
||||||
chat_talking_prompt = get_recent_group_detailed_plain_text(self.db, stream_id, limit=global_config.MAX_CONTEXT_SIZE,combine = True)
|
chat_talking_prompt = get_recent_group_detailed_plain_text(stream_id, limit=global_config.MAX_CONTEXT_SIZE,combine = True)
|
||||||
chat_stream=chat_manager.get_stream(stream_id)
|
chat_stream=chat_manager.get_stream(stream_id)
|
||||||
if chat_stream.group_info:
|
if chat_stream.group_info:
|
||||||
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
chat_talking_prompt = f"以下是群里正在聊天的内容:\n{chat_talking_prompt}"
|
||||||
|
|
@ -199,7 +198,7 @@ class PromptBuilder:
|
||||||
|
|
||||||
chat_talking_prompt = ''
|
chat_talking_prompt = ''
|
||||||
if group_id:
|
if group_id:
|
||||||
chat_talking_prompt = get_recent_group_detailed_plain_text(self.db, group_id,
|
chat_talking_prompt = get_recent_group_detailed_plain_text(group_id,
|
||||||
limit=global_config.MAX_CONTEXT_SIZE,
|
limit=global_config.MAX_CONTEXT_SIZE,
|
||||||
combine=True)
|
combine=True)
|
||||||
|
|
||||||
|
|
@ -311,7 +310,7 @@ class PromptBuilder:
|
||||||
{"$project": {"content": 1, "similarity": 1}}
|
{"$project": {"content": 1, "similarity": 1}}
|
||||||
]
|
]
|
||||||
|
|
||||||
results = list(self.db.knowledges.aggregate(pipeline))
|
results = list(db.knowledges.aggregate(pipeline))
|
||||||
# print(f"\033[1;34m[调试]\033[0m获取知识库内容结果: {results}")
|
# print(f"\033[1;34m[调试]\033[0m获取知识库内容结果: {results}")
|
||||||
|
|
||||||
if not results:
|
if not results:
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@ import asyncio
|
||||||
from typing import Optional
|
from typing import Optional
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from .message_base import UserInfo
|
from .message_base import UserInfo
|
||||||
from .chat_stream import ChatStream
|
from .chat_stream import ChatStream
|
||||||
|
|
||||||
|
|
@ -167,14 +167,12 @@ class RelationshipManager:
|
||||||
|
|
||||||
async def load_all_relationships(self):
|
async def load_all_relationships(self):
|
||||||
"""加载所有关系对象"""
|
"""加载所有关系对象"""
|
||||||
db = Database.get_instance()
|
|
||||||
all_relationships = db.relationships.find({})
|
all_relationships = db.relationships.find({})
|
||||||
for data in all_relationships:
|
for data in all_relationships:
|
||||||
await self.load_relationship(data)
|
await self.load_relationship(data)
|
||||||
|
|
||||||
async def _start_relationship_manager(self):
|
async def _start_relationship_manager(self):
|
||||||
"""每5分钟自动保存一次关系数据"""
|
"""每5分钟自动保存一次关系数据"""
|
||||||
db = Database.get_instance()
|
|
||||||
# 获取所有关系记录
|
# 获取所有关系记录
|
||||||
all_relationships = db.relationships.find({})
|
all_relationships = db.relationships.find({})
|
||||||
# 依次加载每条记录
|
# 依次加载每条记录
|
||||||
|
|
@ -205,7 +203,6 @@ class RelationshipManager:
|
||||||
age = relationship.age
|
age = relationship.age
|
||||||
saved = relationship.saved
|
saved = relationship.saved
|
||||||
|
|
||||||
db = Database.get_instance()
|
|
||||||
db.relationships.update_one(
|
db.relationships.update_one(
|
||||||
{'user_id': user_id, 'platform': platform},
|
{'user_id': user_id, 'platform': platform},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
|
|
|
||||||
|
|
@ -1,15 +1,12 @@
|
||||||
from typing import Optional, Union
|
from typing import Optional, Union
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from .message import MessageSending, MessageRecv
|
from .message import MessageSending, MessageRecv
|
||||||
from .chat_stream import ChatStream
|
from .chat_stream import ChatStream
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
|
|
||||||
class MessageStorage:
|
class MessageStorage:
|
||||||
def __init__(self):
|
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
async def store_message(self, message: Union[MessageSending, MessageRecv],chat_stream:ChatStream, topic: Optional[str] = None) -> None:
|
async def store_message(self, message: Union[MessageSending, MessageRecv],chat_stream:ChatStream, topic: Optional[str] = None) -> None:
|
||||||
"""存储消息到数据库"""
|
"""存储消息到数据库"""
|
||||||
try:
|
try:
|
||||||
|
|
@ -23,7 +20,7 @@ class MessageStorage:
|
||||||
"detailed_plain_text": message.detailed_plain_text,
|
"detailed_plain_text": message.detailed_plain_text,
|
||||||
"topic": topic,
|
"topic": topic,
|
||||||
}
|
}
|
||||||
self.db.messages.insert_one(message_data)
|
db.messages.insert_one(message_data)
|
||||||
except Exception:
|
except Exception:
|
||||||
logger.exception("存储消息失败")
|
logger.exception("存储消息失败")
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -16,6 +16,7 @@ from .message import MessageRecv,Message
|
||||||
from .message_base import UserInfo
|
from .message_base import UserInfo
|
||||||
from .chat_stream import ChatStream
|
from .chat_stream import ChatStream
|
||||||
from ..moods.moods import MoodManager
|
from ..moods.moods import MoodManager
|
||||||
|
from ...common.database import db
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
@ -76,11 +77,10 @@ def calculate_information_content(text):
|
||||||
return entropy
|
return entropy
|
||||||
|
|
||||||
|
|
||||||
def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
def get_closest_chat_from_db(length: int, timestamp: str):
|
||||||
"""从数据库中获取最接近指定时间戳的聊天记录
|
"""从数据库中获取最接近指定时间戳的聊天记录
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
db: 数据库实例
|
|
||||||
length: 要获取的消息数量
|
length: 要获取的消息数量
|
||||||
timestamp: 时间戳
|
timestamp: 时间戳
|
||||||
|
|
||||||
|
|
@ -115,11 +115,10 @@ def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
||||||
return []
|
return []
|
||||||
|
|
||||||
|
|
||||||
async def get_recent_group_messages(db, chat_id:str, limit: int = 12) -> list:
|
async def get_recent_group_messages(chat_id:str, limit: int = 12) -> list:
|
||||||
"""从数据库获取群组最近的消息记录
|
"""从数据库获取群组最近的消息记录
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
db: Database实例
|
|
||||||
group_id: 群组ID
|
group_id: 群组ID
|
||||||
limit: 获取消息数量,默认12条
|
limit: 获取消息数量,默认12条
|
||||||
|
|
||||||
|
|
@ -161,7 +160,7 @@ async def get_recent_group_messages(db, chat_id:str, limit: int = 12) -> list:
|
||||||
return message_objects
|
return message_objects
|
||||||
|
|
||||||
|
|
||||||
def get_recent_group_detailed_plain_text(db, chat_stream_id: int, limit: int = 12, combine=False):
|
def get_recent_group_detailed_plain_text(chat_stream_id: int, limit: int = 12, combine=False):
|
||||||
recent_messages = list(db.messages.find(
|
recent_messages = list(db.messages.find(
|
||||||
{"chat_id": chat_stream_id},
|
{"chat_id": chat_stream_id},
|
||||||
{
|
{
|
||||||
|
|
|
||||||
|
|
@ -10,231 +10,95 @@ import io
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
|
|
||||||
class ImageManager:
|
class ImageManager:
|
||||||
_instance = None
|
_instance = None
|
||||||
IMAGE_DIR = "data" # 图像存储根目录
|
IMAGE_DIR = "data" # 图像存储根目录
|
||||||
|
|
||||||
def __new__(cls):
|
def __new__(cls):
|
||||||
if cls._instance is None:
|
if cls._instance is None:
|
||||||
cls._instance = super().__new__(cls)
|
cls._instance = super().__new__(cls)
|
||||||
cls._instance.db = None
|
|
||||||
cls._instance._initialized = False
|
cls._instance._initialized = False
|
||||||
return cls._instance
|
return cls._instance
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
if not self._initialized:
|
if not self._initialized:
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._ensure_image_collection()
|
self._ensure_image_collection()
|
||||||
self._ensure_description_collection()
|
self._ensure_description_collection()
|
||||||
self._ensure_image_dir()
|
self._ensure_image_dir()
|
||||||
self._initialized = True
|
self._initialized = True
|
||||||
self._llm = LLM_request(model=global_config.vlm, temperature=0.4, max_tokens=300)
|
self._llm = LLM_request(model=global_config.vlm, temperature=0.4, max_tokens=300)
|
||||||
|
|
||||||
def _ensure_image_dir(self):
|
def _ensure_image_dir(self):
|
||||||
"""确保图像存储目录存在"""
|
"""确保图像存储目录存在"""
|
||||||
os.makedirs(self.IMAGE_DIR, exist_ok=True)
|
os.makedirs(self.IMAGE_DIR, exist_ok=True)
|
||||||
|
|
||||||
def _ensure_image_collection(self):
|
def _ensure_image_collection(self):
|
||||||
"""确保images集合存在并创建索引"""
|
"""确保images集合存在并创建索引"""
|
||||||
if 'images' not in self.db.list_collection_names():
|
if "images" not in db.list_collection_names():
|
||||||
self.db.create_collection('images')
|
db.create_collection("images")
|
||||||
# 创建索引
|
|
||||||
self.db.images.create_index([('hash', 1)], unique=True)
|
# 删除旧索引
|
||||||
self.db.images.create_index([('url', 1)])
|
db.images.drop_indexes()
|
||||||
self.db.images.create_index([('path', 1)])
|
# 创建新的复合索引
|
||||||
|
db.images.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||||
|
db.images.create_index([("url", 1)])
|
||||||
|
db.images.create_index([("path", 1)])
|
||||||
|
|
||||||
def _ensure_description_collection(self):
|
def _ensure_description_collection(self):
|
||||||
"""确保image_descriptions集合存在并创建索引"""
|
"""确保image_descriptions集合存在并创建索引"""
|
||||||
if 'image_descriptions' not in self.db.list_collection_names():
|
if "image_descriptions" not in db.list_collection_names():
|
||||||
self.db.create_collection('image_descriptions')
|
db.create_collection("image_descriptions")
|
||||||
# 创建索引
|
|
||||||
self.db.image_descriptions.create_index([('hash', 1)], unique=True)
|
# 删除旧索引
|
||||||
self.db.image_descriptions.create_index([('type', 1)])
|
db.image_descriptions.drop_indexes()
|
||||||
|
# 创建新的复合索引
|
||||||
|
db.image_descriptions.create_index([("hash", 1), ("type", 1)], unique=True)
|
||||||
|
|
||||||
def _get_description_from_db(self, image_hash: str, description_type: str) -> Optional[str]:
|
def _get_description_from_db(self, image_hash: str, description_type: str) -> Optional[str]:
|
||||||
"""从数据库获取图片描述
|
"""从数据库获取图片描述
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
image_hash: 图片哈希值
|
image_hash: 图片哈希值
|
||||||
description_type: 描述类型 ('emoji' 或 'image')
|
description_type: 描述类型 ('emoji' 或 'image')
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
Optional[str]: 描述文本,如果不存在则返回None
|
Optional[str]: 描述文本,如果不存在则返回None
|
||||||
"""
|
"""
|
||||||
result= self.db.image_descriptions.find_one({
|
result = db.image_descriptions.find_one({"hash": image_hash, "type": description_type})
|
||||||
'hash': image_hash,
|
return result["description"] if result else None
|
||||||
'type': description_type
|
|
||||||
})
|
|
||||||
return result['description'] if result else None
|
|
||||||
|
|
||||||
def _save_description_to_db(self, image_hash: str, description: str, description_type: str) -> None:
|
def _save_description_to_db(self, image_hash: str, description: str, description_type: str) -> None:
|
||||||
"""保存图片描述到数据库
|
"""保存图片描述到数据库
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
image_hash: 图片哈希值
|
image_hash: 图片哈希值
|
||||||
description: 描述文本
|
description: 描述文本
|
||||||
description_type: 描述类型 ('emoji' 或 'image')
|
description_type: 描述类型 ('emoji' 或 'image')
|
||||||
"""
|
"""
|
||||||
self.db.image_descriptions.update_one(
|
try:
|
||||||
{'hash': image_hash, 'type': description_type},
|
db.image_descriptions.update_one(
|
||||||
{
|
{"hash": image_hash, "type": description_type},
|
||||||
'$set': {
|
{
|
||||||
'description': description,
|
"$set": {
|
||||||
'timestamp': int(time.time())
|
"description": description,
|
||||||
}
|
"timestamp": int(time.time()),
|
||||||
},
|
"hash": image_hash, # 确保hash字段存在
|
||||||
upsert=True
|
"type": description_type, # 确保type字段存在
|
||||||
)
|
}
|
||||||
|
},
|
||||||
|
upsert=True,
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
logger.error(f"保存描述到数据库失败: {str(e)}")
|
||||||
|
|
||||||
async def save_image(self,
|
|
||||||
image_data: Union[str, bytes],
|
|
||||||
url: str = None,
|
|
||||||
description: str = None,
|
|
||||||
is_base64: bool = False) -> Optional[str]:
|
|
||||||
"""保存图像
|
|
||||||
Args:
|
|
||||||
image_data: 图像数据(base64字符串或字节)
|
|
||||||
url: 图像URL
|
|
||||||
description: 图像描述
|
|
||||||
is_base64: image_data是否为base64格式
|
|
||||||
Returns:
|
|
||||||
str: 保存后的文件路径,失败返回None
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
# 转换为字节格式
|
|
||||||
if is_base64:
|
|
||||||
if isinstance(image_data, str):
|
|
||||||
image_bytes = base64.b64decode(image_data)
|
|
||||||
else:
|
|
||||||
return None
|
|
||||||
else:
|
|
||||||
if isinstance(image_data, bytes):
|
|
||||||
image_bytes = image_data
|
|
||||||
else:
|
|
||||||
return None
|
|
||||||
|
|
||||||
# 计算哈希值
|
|
||||||
image_hash = hashlib.md5(image_bytes).hexdigest()
|
|
||||||
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
|
||||||
|
|
||||||
# 查重
|
|
||||||
existing = self.db.images.find_one({'hash': image_hash})
|
|
||||||
if existing:
|
|
||||||
return existing['path']
|
|
||||||
|
|
||||||
# 生成文件名和路径
|
|
||||||
timestamp = int(time.time())
|
|
||||||
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
|
||||||
file_path = os.path.join(self.IMAGE_DIR, filename)
|
|
||||||
|
|
||||||
# 保存文件
|
|
||||||
with open(file_path, "wb") as f:
|
|
||||||
f.write(image_bytes)
|
|
||||||
|
|
||||||
# 保存到数据库
|
|
||||||
image_doc = {
|
|
||||||
'hash': image_hash,
|
|
||||||
'path': file_path,
|
|
||||||
'url': url,
|
|
||||||
'description': description,
|
|
||||||
'timestamp': timestamp
|
|
||||||
}
|
|
||||||
self.db.images.insert_one(image_doc)
|
|
||||||
|
|
||||||
return file_path
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"保存图像失败: {str(e)}")
|
|
||||||
return None
|
|
||||||
|
|
||||||
async def get_image_by_url(self, url: str) -> Optional[str]:
|
|
||||||
"""根据URL获取图像路径(带查重)
|
|
||||||
Args:
|
|
||||||
url: 图像URL
|
|
||||||
Returns:
|
|
||||||
str: 本地文件路径,不存在返回None
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
# 先查找是否已存在
|
|
||||||
existing = self.db.images.find_one({'url': url})
|
|
||||||
if existing:
|
|
||||||
return existing['path']
|
|
||||||
|
|
||||||
# 下载图像
|
|
||||||
async with aiohttp.ClientSession() as session:
|
|
||||||
async with session.get(url) as resp:
|
|
||||||
if resp.status == 200:
|
|
||||||
image_bytes = await resp.read()
|
|
||||||
return await self.save_image(image_bytes, url=url)
|
|
||||||
return None
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"获取图像失败: {str(e)}")
|
|
||||||
return None
|
|
||||||
|
|
||||||
async def get_base64_by_url(self, url: str) -> Optional[str]:
|
|
||||||
"""根据URL获取base64(带查重)
|
|
||||||
Args:
|
|
||||||
url: 图像URL
|
|
||||||
Returns:
|
|
||||||
str: base64字符串,失败返回None
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
image_path = await self.get_image_by_url(url)
|
|
||||||
if not image_path:
|
|
||||||
return None
|
|
||||||
|
|
||||||
with open(image_path, 'rb') as f:
|
|
||||||
image_bytes = f.read()
|
|
||||||
return base64.b64encode(image_bytes).decode('utf-8')
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"获取base64失败: {str(e)}")
|
|
||||||
return None
|
|
||||||
|
|
||||||
|
|
||||||
def check_url_exists(self, url: str) -> bool:
|
|
||||||
"""检查URL是否已存在
|
|
||||||
Args:
|
|
||||||
url: 图像URL
|
|
||||||
Returns:
|
|
||||||
bool: 是否存在
|
|
||||||
"""
|
|
||||||
return self.db.images.find_one({'url': url}) is not None
|
|
||||||
|
|
||||||
def check_hash_exists(self, image_data: Union[str, bytes], is_base64: bool = False) -> bool:
|
|
||||||
"""检查图像是否已存在
|
|
||||||
Args:
|
|
||||||
image_data: 图像数据(base64或字节)
|
|
||||||
is_base64: 是否为base64格式
|
|
||||||
Returns:
|
|
||||||
bool: 是否存在
|
|
||||||
"""
|
|
||||||
try:
|
|
||||||
if is_base64:
|
|
||||||
if isinstance(image_data, str):
|
|
||||||
image_bytes = base64.b64decode(image_data)
|
|
||||||
else:
|
|
||||||
return False
|
|
||||||
else:
|
|
||||||
if isinstance(image_data, bytes):
|
|
||||||
image_bytes = image_data
|
|
||||||
else:
|
|
||||||
return False
|
|
||||||
|
|
||||||
image_hash = hashlib.md5(image_bytes).hexdigest()
|
|
||||||
return self.db.images.find_one({'hash': image_hash}) is not None
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"检查哈希失败: {str(e)}")
|
|
||||||
return False
|
|
||||||
|
|
||||||
async def get_emoji_description(self, image_base64: str) -> str:
|
async def get_emoji_description(self, image_base64: str) -> str:
|
||||||
"""获取表情包描述,带查重和保存功能"""
|
"""获取表情包描述,带查重和保存功能"""
|
||||||
try:
|
try:
|
||||||
|
|
@ -244,7 +108,7 @@ class ImageManager:
|
||||||
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
|
|
||||||
# 查询缓存的描述
|
# 查询缓存的描述
|
||||||
cached_description = self._get_description_from_db(image_hash, 'emoji')
|
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||||
if cached_description:
|
if cached_description:
|
||||||
logger.info(f"缓存表情包描述: {cached_description}")
|
logger.info(f"缓存表情包描述: {cached_description}")
|
||||||
return f"[表情包:{cached_description}]"
|
return f"[表情包:{cached_description}]"
|
||||||
|
|
@ -252,39 +116,42 @@ class ImageManager:
|
||||||
# 调用AI获取描述
|
# 调用AI获取描述
|
||||||
prompt = "这是一个表情包,使用中文简洁的描述一下表情包的内容和表情包所表达的情感"
|
prompt = "这是一个表情包,使用中文简洁的描述一下表情包的内容和表情包所表达的情感"
|
||||||
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
|
|
||||||
|
cached_description = self._get_description_from_db(image_hash, "emoji")
|
||||||
|
if cached_description:
|
||||||
|
logger.warning(f"虽然生成了描述,但是找到缓存表情包描述: {cached_description}")
|
||||||
|
return f"[表情包:{cached_description}]"
|
||||||
|
|
||||||
# 根据配置决定是否保存图片
|
# 根据配置决定是否保存图片
|
||||||
if global_config.EMOJI_SAVE:
|
if global_config.EMOJI_SAVE:
|
||||||
# 生成文件名和路径
|
# 生成文件名和路径
|
||||||
timestamp = int(time.time())
|
timestamp = int(time.time())
|
||||||
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
||||||
file_path = os.path.join(self.IMAGE_DIR, 'emoji',filename)
|
if not os.path.exists(os.path.join(self.IMAGE_DIR, "emoji")):
|
||||||
|
os.makedirs(os.path.join(self.IMAGE_DIR, "emoji"))
|
||||||
|
file_path = os.path.join(self.IMAGE_DIR, "emoji", filename)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
# 保存文件
|
# 保存文件
|
||||||
with open(file_path, "wb") as f:
|
with open(file_path, "wb") as f:
|
||||||
f.write(image_bytes)
|
f.write(image_bytes)
|
||||||
|
|
||||||
# 保存到数据库
|
# 保存到数据库
|
||||||
image_doc = {
|
image_doc = {
|
||||||
'hash': image_hash,
|
"hash": image_hash,
|
||||||
'path': file_path,
|
"path": file_path,
|
||||||
'type': 'emoji',
|
"type": "emoji",
|
||||||
'description': description,
|
"description": description,
|
||||||
'timestamp': timestamp
|
"timestamp": timestamp,
|
||||||
}
|
}
|
||||||
self.db.images.update_one(
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
{'hash': image_hash},
|
|
||||||
{'$set': image_doc},
|
|
||||||
upsert=True
|
|
||||||
)
|
|
||||||
logger.success(f"保存表情包: {file_path}")
|
logger.success(f"保存表情包: {file_path}")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"保存表情包文件失败: {str(e)}")
|
logger.error(f"保存表情包文件失败: {str(e)}")
|
||||||
|
|
||||||
# 保存描述到数据库
|
# 保存描述到数据库
|
||||||
self._save_description_to_db(image_hash, description, 'emoji')
|
self._save_description_to_db(image_hash, description, "emoji")
|
||||||
|
|
||||||
return f"[表情包:{description}]"
|
return f"[表情包:{description}]"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"获取表情包描述失败: {str(e)}")
|
logger.error(f"获取表情包描述失败: {str(e)}")
|
||||||
|
|
@ -293,67 +160,70 @@ class ImageManager:
|
||||||
async def get_image_description(self, image_base64: str) -> str:
|
async def get_image_description(self, image_base64: str) -> str:
|
||||||
"""获取普通图片描述,带查重和保存功能"""
|
"""获取普通图片描述,带查重和保存功能"""
|
||||||
try:
|
try:
|
||||||
print("处理图片中")
|
|
||||||
# 计算图片哈希
|
# 计算图片哈希
|
||||||
image_bytes = base64.b64decode(image_base64)
|
image_bytes = base64.b64decode(image_base64)
|
||||||
image_hash = hashlib.md5(image_bytes).hexdigest()
|
image_hash = hashlib.md5(image_bytes).hexdigest()
|
||||||
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
image_format = Image.open(io.BytesIO(image_bytes)).format.lower()
|
||||||
|
|
||||||
# 查询缓存的描述
|
# 查询缓存的描述
|
||||||
cached_description = self._get_description_from_db(image_hash, 'image')
|
cached_description = self._get_description_from_db(image_hash, "image")
|
||||||
if cached_description:
|
if cached_description:
|
||||||
print("图片描述缓存中")
|
logger.info(f"图片描述缓存中 {cached_description}")
|
||||||
return f"[图片:{cached_description}]"
|
return f"[图片:{cached_description}]"
|
||||||
|
|
||||||
# 调用AI获取描述
|
# 调用AI获取描述
|
||||||
prompt = "请用中文描述这张图片的内容。如果有文字,请把文字都描述出来。并尝试猜测这个图片的含义。最多200个字。"
|
prompt = (
|
||||||
|
"请用中文描述这张图片的内容。如果有文字,请把文字都描述出来。并尝试猜测这个图片的含义。最多200个字。"
|
||||||
|
)
|
||||||
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
description, _ = await self._llm.generate_response_for_image(prompt, image_base64, image_format)
|
||||||
|
|
||||||
print(f"描述是{description}")
|
cached_description = self._get_description_from_db(image_hash, "image")
|
||||||
|
if cached_description:
|
||||||
|
logger.warning(f"虽然生成了描述,但是找到缓存图片描述 {cached_description}")
|
||||||
|
return f"[图片:{cached_description}]"
|
||||||
|
|
||||||
|
logger.info(f"描述是{description}")
|
||||||
|
|
||||||
if description is None:
|
if description is None:
|
||||||
logger.warning("AI未能生成图片描述")
|
logger.warning("AI未能生成图片描述")
|
||||||
return "[图片]"
|
return "[图片]"
|
||||||
|
|
||||||
# 根据配置决定是否保存图片
|
# 根据配置决定是否保存图片
|
||||||
if global_config.EMOJI_SAVE:
|
if global_config.EMOJI_SAVE:
|
||||||
# 生成文件名和路径
|
# 生成文件名和路径
|
||||||
timestamp = int(time.time())
|
timestamp = int(time.time())
|
||||||
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
filename = f"{timestamp}_{image_hash[:8]}.{image_format}"
|
||||||
file_path = os.path.join(self.IMAGE_DIR,'image', filename)
|
if not os.path.exists(os.path.join(self.IMAGE_DIR, "image")):
|
||||||
|
os.makedirs(os.path.join(self.IMAGE_DIR, "image"))
|
||||||
|
file_path = os.path.join(self.IMAGE_DIR, "image", filename)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
# 保存文件
|
# 保存文件
|
||||||
with open(file_path, "wb") as f:
|
with open(file_path, "wb") as f:
|
||||||
f.write(image_bytes)
|
f.write(image_bytes)
|
||||||
|
|
||||||
# 保存到数据库
|
# 保存到数据库
|
||||||
image_doc = {
|
image_doc = {
|
||||||
'hash': image_hash,
|
"hash": image_hash,
|
||||||
'path': file_path,
|
"path": file_path,
|
||||||
'type': 'image',
|
"type": "image",
|
||||||
'description': description,
|
"description": description,
|
||||||
'timestamp': timestamp
|
"timestamp": timestamp,
|
||||||
}
|
}
|
||||||
self.db.images.update_one(
|
db.images.update_one({"hash": image_hash}, {"$set": image_doc}, upsert=True)
|
||||||
{'hash': image_hash},
|
|
||||||
{'$set': image_doc},
|
|
||||||
upsert=True
|
|
||||||
)
|
|
||||||
logger.success(f"保存图片: {file_path}")
|
logger.success(f"保存图片: {file_path}")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"保存图片文件失败: {str(e)}")
|
logger.error(f"保存图片文件失败: {str(e)}")
|
||||||
|
|
||||||
# 保存描述到数据库
|
# 保存描述到数据库
|
||||||
self._save_description_to_db(image_hash, description, 'image')
|
self._save_description_to_db(image_hash, description, "image")
|
||||||
|
|
||||||
return f"[图片:{description}]"
|
return f"[图片:{description}]"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"获取图片描述失败: {str(e)}")
|
logger.error(f"获取图片描述失败: {str(e)}")
|
||||||
return "[图片]"
|
return "[图片]"
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# 创建全局单例
|
# 创建全局单例
|
||||||
image_manager = ImageManager()
|
image_manager = ImageManager()
|
||||||
|
|
||||||
|
|
@ -366,9 +236,9 @@ def image_path_to_base64(image_path: str) -> str:
|
||||||
str: base64编码的图片数据
|
str: base64编码的图片数据
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
with open(image_path, 'rb') as f:
|
with open(image_path, "rb") as f:
|
||||||
image_data = f.read()
|
image_data = f.read()
|
||||||
return base64.b64encode(image_data).decode('utf-8')
|
return base64.b64encode(image_data).decode("utf-8")
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"读取图片失败: {image_path}, 错误: {str(e)}")
|
logger.error(f"读取图片失败: {image_path}, 错误: {str(e)}")
|
||||||
return None
|
return None
|
||||||
|
|
|
||||||
|
|
@ -5,14 +5,16 @@ from .relationship_manager import relationship_manager
|
||||||
def get_user_nickname(user_id: int) -> str:
|
def get_user_nickname(user_id: int) -> str:
|
||||||
if int(user_id) == int(global_config.BOT_QQ):
|
if int(user_id) == int(global_config.BOT_QQ):
|
||||||
return global_config.BOT_NICKNAME
|
return global_config.BOT_NICKNAME
|
||||||
# print(user_id)
|
# print(user_id)
|
||||||
return relationship_manager.get_name(user_id)
|
return relationship_manager.get_name(user_id)
|
||||||
|
|
||||||
|
|
||||||
def get_user_cardname(user_id: int) -> str:
|
def get_user_cardname(user_id: int) -> str:
|
||||||
if int(user_id) == int(global_config.BOT_QQ):
|
if int(user_id) == int(global_config.BOT_QQ):
|
||||||
return global_config.BOT_NICKNAME
|
return global_config.BOT_NICKNAME
|
||||||
# print(user_id)
|
# print(user_id)
|
||||||
return ''
|
return ""
|
||||||
|
|
||||||
|
|
||||||
def get_groupname(group_id: int) -> str:
|
def get_groupname(group_id: int) -> str:
|
||||||
return f"群{group_id}"
|
return f"群{group_id}"
|
||||||
|
|
|
||||||
|
|
@ -55,14 +55,14 @@ class WillingManager:
|
||||||
for chat_id in list(self.chat_high_willing_mode.keys()):
|
for chat_id in list(self.chat_high_willing_mode.keys()):
|
||||||
last_change_time = self.chat_last_mode_change.get(chat_id, 0)
|
last_change_time = self.chat_last_mode_change.get(chat_id, 0)
|
||||||
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
is_high_mode = self.chat_high_willing_mode.get(chat_id, False)
|
||||||
|
|
||||||
# 获取当前模式的持续时间
|
# 获取当前模式的持续时间
|
||||||
duration = 0
|
duration = 0
|
||||||
if is_high_mode:
|
if is_high_mode:
|
||||||
duration = self.chat_high_willing_duration.get(chat_id, 180) # 使用已存储的持续时间或默认3分钟
|
duration = self.chat_high_willing_duration.get(chat_id, 180) # 使用已存储的持续时间或默认3分钟
|
||||||
else:
|
else:
|
||||||
duration = self.chat_low_willing_duration.get(chat_id, 300) # 使用已存储的持续时间或默认5分钟
|
duration = self.chat_low_willing_duration.get(chat_id, 300) # 使用已存储的持续时间或默认5分钟
|
||||||
|
|
||||||
# 检查是否需要切换模式
|
# 检查是否需要切换模式
|
||||||
if current_time - last_change_time > duration:
|
if current_time - last_change_time > duration:
|
||||||
self._switch_willing_mode(chat_id)
|
self._switch_willing_mode(chat_id)
|
||||||
|
|
@ -111,7 +111,7 @@ class WillingManager:
|
||||||
def _ensure_chat_initialized(self, chat_id: str):
|
def _ensure_chat_initialized(self, chat_id: str):
|
||||||
"""确保聊天流的所有数据已初始化"""
|
"""确保聊天流的所有数据已初始化"""
|
||||||
current_time = time.time()
|
current_time = time.time()
|
||||||
|
|
||||||
if chat_id not in self.chat_reply_willing:
|
if chat_id not in self.chat_reply_willing:
|
||||||
self.chat_reply_willing[chat_id] = 0.1
|
self.chat_reply_willing[chat_id] = 0.1
|
||||||
|
|
||||||
|
|
@ -263,7 +263,7 @@ class WillingManager:
|
||||||
# 冷群中提高回复概率为三倍
|
# 冷群中提高回复概率为三倍
|
||||||
reply_probability = min(reply_probability * 3.0)
|
reply_probability = min(reply_probability * 3.0)
|
||||||
logger.debug(f"检测到冷群 {group_id},提高回复概率到: {reply_probability:.2f}")
|
logger.debug(f"检测到冷群 {group_id},提高回复概率到: {reply_probability:.2f}")
|
||||||
|
|
||||||
# 检查群组权限(如果是群聊)
|
# 检查群组权限(如果是群聊)
|
||||||
if chat_stream.group_info and config:
|
if chat_stream.group_info and config:
|
||||||
if chat_stream.group_info.group_id in config.talk_frequency_down_groups:
|
if chat_stream.group_info.group_id in config.talk_frequency_down_groups:
|
||||||
|
|
|
||||||
|
|
@ -13,7 +13,7 @@ from loguru import logger
|
||||||
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
sys.path.append(root_path)
|
sys.path.append(root_path)
|
||||||
|
|
||||||
from src.common.database import Database # 使用正确的导入语法
|
from src.common.database import db # 使用正确的导入语法
|
||||||
|
|
||||||
# 加载.env.dev文件
|
# 加载.env.dev文件
|
||||||
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))), '.env.dev')
|
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))), '.env.dev')
|
||||||
|
|
@ -23,7 +23,6 @@ load_dotenv(env_path)
|
||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
self.G.add_edge(concept1, concept2)
|
self.G.add_edge(concept1, concept2)
|
||||||
|
|
@ -96,7 +95,7 @@ class Memory_graph:
|
||||||
dot_data = {
|
dot_data = {
|
||||||
"concept": node
|
"concept": node
|
||||||
}
|
}
|
||||||
self.db.store_memory_dots.insert_one(dot_data)
|
db.store_memory_dots.insert_one(dot_data)
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def dots(self):
|
def dots(self):
|
||||||
|
|
@ -106,7 +105,7 @@ class Memory_graph:
|
||||||
def get_random_chat_from_db(self, length: int, timestamp: str):
|
def get_random_chat_from_db(self, length: int, timestamp: str):
|
||||||
# 从数据库中根据时间戳获取离其最近的聊天记录
|
# 从数据库中根据时间戳获取离其最近的聊天记录
|
||||||
chat_text = ''
|
chat_text = ''
|
||||||
closest_record = self.db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)]) # 调试输出
|
closest_record = db.messages.find_one({"time": {"$lte": timestamp}}, sort=[('time', -1)]) # 调试输出
|
||||||
logger.info(
|
logger.info(
|
||||||
f"距离time最近的消息时间: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(closest_record['time'])))}")
|
f"距离time最近的消息时间: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(closest_record['time'])))}")
|
||||||
|
|
||||||
|
|
@ -115,7 +114,7 @@ class Memory_graph:
|
||||||
group_id = closest_record['group_id'] # 获取groupid
|
group_id = closest_record['group_id'] # 获取groupid
|
||||||
# 获取该时间戳之后的length条消息,且groupid相同
|
# 获取该时间戳之后的length条消息,且groupid相同
|
||||||
chat_record = list(
|
chat_record = list(
|
||||||
self.db.messages.find({"time": {"$gt": closest_time}, "group_id": group_id}).sort('time', 1).limit(
|
db.messages.find({"time": {"$gt": closest_time}, "group_id": group_id}).sort('time', 1).limit(
|
||||||
length))
|
length))
|
||||||
for record in chat_record:
|
for record in chat_record:
|
||||||
time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(record['time'])))
|
time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(record['time'])))
|
||||||
|
|
@ -130,50 +129,39 @@ class Memory_graph:
|
||||||
|
|
||||||
def save_graph_to_db(self):
|
def save_graph_to_db(self):
|
||||||
# 清空现有的图数据
|
# 清空现有的图数据
|
||||||
self.db.graph_data.delete_many({})
|
db.graph_data.delete_many({})
|
||||||
# 保存节点
|
# 保存节点
|
||||||
for node in self.G.nodes(data=True):
|
for node in self.G.nodes(data=True):
|
||||||
node_data = {
|
node_data = {
|
||||||
'concept': node[0],
|
'concept': node[0],
|
||||||
'memory_items': node[1].get('memory_items', []) # 默认为空列表
|
'memory_items': node[1].get('memory_items', []) # 默认为空列表
|
||||||
}
|
}
|
||||||
self.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
# 保存边
|
# 保存边
|
||||||
for edge in self.G.edges():
|
for edge in self.G.edges():
|
||||||
edge_data = {
|
edge_data = {
|
||||||
'source': edge[0],
|
'source': edge[0],
|
||||||
'target': edge[1]
|
'target': edge[1]
|
||||||
}
|
}
|
||||||
self.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
|
|
||||||
def load_graph_from_db(self):
|
def load_graph_from_db(self):
|
||||||
# 清空当前图
|
# 清空当前图
|
||||||
self.G.clear()
|
self.G.clear()
|
||||||
# 加载节点
|
# 加载节点
|
||||||
nodes = self.db.graph_data.nodes.find()
|
nodes = db.graph_data.nodes.find()
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
if not isinstance(memory_items, list):
|
if not isinstance(memory_items, list):
|
||||||
memory_items = [memory_items] if memory_items else []
|
memory_items = [memory_items] if memory_items else []
|
||||||
self.G.add_node(node['concept'], memory_items=memory_items)
|
self.G.add_node(node['concept'], memory_items=memory_items)
|
||||||
# 加载边
|
# 加载边
|
||||||
edges = self.db.graph_data.edges.find()
|
edges = db.graph_data.edges.find()
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
self.G.add_edge(edge['source'], edge['target'])
|
self.G.add_edge(edge['source'], edge['target'])
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
# 初始化数据库
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
|
|
||||||
memory_graph = Memory_graph()
|
memory_graph = Memory_graph()
|
||||||
memory_graph.load_graph_from_db()
|
memory_graph.load_graph_from_db()
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -10,12 +10,12 @@ import networkx as nx
|
||||||
|
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
from nonebot import get_driver
|
from nonebot import get_driver
|
||||||
from ...common.database import Database # 使用正确的导入语法
|
from ...common.database import db # 使用正确的导入语法
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
from ..chat.utils import (
|
from ..chat.utils import (
|
||||||
calculate_information_content,
|
calculate_information_content,
|
||||||
cosine_similarity,
|
cosine_similarity,
|
||||||
get_cloest_chat_from_db,
|
get_closest_chat_from_db,
|
||||||
text_to_vector,
|
text_to_vector,
|
||||||
)
|
)
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
@ -23,7 +23,6 @@ from ..models.utils_model import LLM_request
|
||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
# 避免自连接
|
# 避免自连接
|
||||||
|
|
@ -191,19 +190,19 @@ class Hippocampus:
|
||||||
# 短期:1h 中期:4h 长期:24h
|
# 短期:1h 中期:4h 长期:24h
|
||||||
for _ in range(time_frequency.get('near')):
|
for _ in range(time_frequency.get('near')):
|
||||||
random_time = current_timestamp - random.randint(1, 3600)
|
random_time = current_timestamp - random.randint(1, 3600)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('mid')):
|
for _ in range(time_frequency.get('mid')):
|
||||||
random_time = current_timestamp - random.randint(3600, 3600 * 4)
|
random_time = current_timestamp - random.randint(3600, 3600 * 4)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('far')):
|
for _ in range(time_frequency.get('far')):
|
||||||
random_time = current_timestamp - random.randint(3600 * 4, 3600 * 24)
|
random_time = current_timestamp - random.randint(3600 * 4, 3600 * 24)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
|
|
@ -349,7 +348,7 @@ class Hippocampus:
|
||||||
def sync_memory_to_db(self):
|
def sync_memory_to_db(self):
|
||||||
"""检查并同步内存中的图结构与数据库"""
|
"""检查并同步内存中的图结构与数据库"""
|
||||||
# 获取数据库中所有节点和内存中所有节点
|
# 获取数据库中所有节点和内存中所有节点
|
||||||
db_nodes = list(self.memory_graph.db.graph_data.nodes.find())
|
db_nodes = list(db.graph_data.nodes.find())
|
||||||
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
||||||
|
|
||||||
# 转换数据库节点为字典格式,方便查找
|
# 转换数据库节点为字典格式,方便查找
|
||||||
|
|
@ -377,7 +376,7 @@ class Hippocampus:
|
||||||
'created_time': created_time,
|
'created_time': created_time,
|
||||||
'last_modified': last_modified
|
'last_modified': last_modified
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
else:
|
else:
|
||||||
# 获取数据库中节点的特征值
|
# 获取数据库中节点的特征值
|
||||||
db_node = db_nodes_dict[concept]
|
db_node = db_nodes_dict[concept]
|
||||||
|
|
@ -385,7 +384,7 @@ class Hippocampus:
|
||||||
|
|
||||||
# 如果特征值不同,则更新节点
|
# 如果特征值不同,则更新节点
|
||||||
if db_hash != memory_hash:
|
if db_hash != memory_hash:
|
||||||
self.memory_graph.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
|
|
@ -396,7 +395,7 @@ class Hippocampus:
|
||||||
)
|
)
|
||||||
|
|
||||||
# 处理边的信息
|
# 处理边的信息
|
||||||
db_edges = list(self.memory_graph.db.graph_data.edges.find())
|
db_edges = list(db.graph_data.edges.find())
|
||||||
memory_edges = list(self.memory_graph.G.edges(data=True))
|
memory_edges = list(self.memory_graph.G.edges(data=True))
|
||||||
|
|
||||||
# 创建边的哈希值字典
|
# 创建边的哈希值字典
|
||||||
|
|
@ -428,11 +427,11 @@ class Hippocampus:
|
||||||
'created_time': created_time,
|
'created_time': created_time,
|
||||||
'last_modified': last_modified
|
'last_modified': last_modified
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
else:
|
else:
|
||||||
# 检查边的特征值是否变化
|
# 检查边的特征值是否变化
|
||||||
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
||||||
self.memory_graph.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'hash': edge_hash,
|
'hash': edge_hash,
|
||||||
|
|
@ -451,7 +450,7 @@ class Hippocampus:
|
||||||
self.memory_graph.G.clear()
|
self.memory_graph.G.clear()
|
||||||
|
|
||||||
# 从数据库加载所有节点
|
# 从数据库加载所有节点
|
||||||
nodes = list(self.memory_graph.db.graph_data.nodes.find())
|
nodes = list(db.graph_data.nodes.find())
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
concept = node['concept']
|
concept = node['concept']
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
|
|
@ -468,7 +467,7 @@ class Hippocampus:
|
||||||
if 'last_modified' not in node:
|
if 'last_modified' not in node:
|
||||||
update_data['last_modified'] = current_time
|
update_data['last_modified'] = current_time
|
||||||
|
|
||||||
self.memory_graph.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': update_data}
|
{'$set': update_data}
|
||||||
)
|
)
|
||||||
|
|
@ -485,7 +484,7 @@ class Hippocampus:
|
||||||
last_modified=last_modified)
|
last_modified=last_modified)
|
||||||
|
|
||||||
# 从数据库加载所有边
|
# 从数据库加载所有边
|
||||||
edges = list(self.memory_graph.db.graph_data.edges.find())
|
edges = list(db.graph_data.edges.find())
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
source = edge['source']
|
source = edge['source']
|
||||||
target = edge['target']
|
target = edge['target']
|
||||||
|
|
@ -501,7 +500,7 @@ class Hippocampus:
|
||||||
if 'last_modified' not in edge:
|
if 'last_modified' not in edge:
|
||||||
update_data['last_modified'] = current_time
|
update_data['last_modified'] = current_time
|
||||||
|
|
||||||
self.memory_graph.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': update_data}
|
{'$set': update_data}
|
||||||
)
|
)
|
||||||
|
|
|
||||||
|
|
@ -19,7 +19,7 @@ import jieba
|
||||||
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
sys.path.append(root_path)
|
sys.path.append(root_path)
|
||||||
|
|
||||||
from src.common.database import Database
|
from src.common.database import db
|
||||||
from src.plugins.memory_system.offline_llm import LLMModel
|
from src.plugins.memory_system.offline_llm import LLMModel
|
||||||
|
|
||||||
# 获取当前文件的目录
|
# 获取当前文件的目录
|
||||||
|
|
@ -49,7 +49,7 @@ def calculate_information_content(text):
|
||||||
|
|
||||||
return entropy
|
return entropy
|
||||||
|
|
||||||
def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
def get_closest_chat_from_db(length: int, timestamp: str):
|
||||||
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
|
|
@ -91,7 +91,6 @@ def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
# 如果边已存在,增加 strength
|
# 如果边已存在,增加 strength
|
||||||
|
|
@ -186,19 +185,19 @@ class Hippocampus:
|
||||||
# 短期:1h 中期:4h 长期:24h
|
# 短期:1h 中期:4h 长期:24h
|
||||||
for _ in range(time_frequency.get('near')):
|
for _ in range(time_frequency.get('near')):
|
||||||
random_time = current_timestamp - random.randint(1, 3600*4)
|
random_time = current_timestamp - random.randint(1, 3600*4)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('mid')):
|
for _ in range(time_frequency.get('mid')):
|
||||||
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('far')):
|
for _ in range(time_frequency.get('far')):
|
||||||
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
|
|
@ -323,7 +322,7 @@ class Hippocampus:
|
||||||
self.memory_graph.G.clear()
|
self.memory_graph.G.clear()
|
||||||
|
|
||||||
# 从数据库加载所有节点
|
# 从数据库加载所有节点
|
||||||
nodes = self.memory_graph.db.graph_data.nodes.find()
|
nodes = db.graph_data.nodes.find()
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
concept = node['concept']
|
concept = node['concept']
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
|
|
@ -334,7 +333,7 @@ class Hippocampus:
|
||||||
self.memory_graph.G.add_node(concept, memory_items=memory_items)
|
self.memory_graph.G.add_node(concept, memory_items=memory_items)
|
||||||
|
|
||||||
# 从数据库加载所有边
|
# 从数据库加载所有边
|
||||||
edges = self.memory_graph.db.graph_data.edges.find()
|
edges = db.graph_data.edges.find()
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
source = edge['source']
|
source = edge['source']
|
||||||
target = edge['target']
|
target = edge['target']
|
||||||
|
|
@ -371,7 +370,7 @@ class Hippocampus:
|
||||||
使用特征值(哈希值)快速判断是否需要更新
|
使用特征值(哈希值)快速判断是否需要更新
|
||||||
"""
|
"""
|
||||||
# 获取数据库中所有节点和内存中所有节点
|
# 获取数据库中所有节点和内存中所有节点
|
||||||
db_nodes = list(self.memory_graph.db.graph_data.nodes.find())
|
db_nodes = list(db.graph_data.nodes.find())
|
||||||
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
||||||
|
|
||||||
# 转换数据库节点为字典格式,方便查找
|
# 转换数据库节点为字典格式,方便查找
|
||||||
|
|
@ -394,7 +393,7 @@ class Hippocampus:
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
'hash': memory_hash
|
'hash': memory_hash
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
else:
|
else:
|
||||||
# 获取数据库中节点的特征值
|
# 获取数据库中节点的特征值
|
||||||
db_node = db_nodes_dict[concept]
|
db_node = db_nodes_dict[concept]
|
||||||
|
|
@ -403,7 +402,7 @@ class Hippocampus:
|
||||||
# 如果特征值不同,则更新节点
|
# 如果特征值不同,则更新节点
|
||||||
if db_hash != memory_hash:
|
if db_hash != memory_hash:
|
||||||
# logger.info(f"更新节点内容: {concept}")
|
# logger.info(f"更新节点内容: {concept}")
|
||||||
self.memory_graph.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
|
|
@ -416,10 +415,10 @@ class Hippocampus:
|
||||||
for db_node in db_nodes:
|
for db_node in db_nodes:
|
||||||
if db_node['concept'] not in memory_concepts:
|
if db_node['concept'] not in memory_concepts:
|
||||||
# logger.info(f"删除多余节点: {db_node['concept']}")
|
# logger.info(f"删除多余节点: {db_node['concept']}")
|
||||||
self.memory_graph.db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
||||||
|
|
||||||
# 处理边的信息
|
# 处理边的信息
|
||||||
db_edges = list(self.memory_graph.db.graph_data.edges.find())
|
db_edges = list(db.graph_data.edges.find())
|
||||||
memory_edges = list(self.memory_graph.G.edges())
|
memory_edges = list(self.memory_graph.G.edges())
|
||||||
|
|
||||||
# 创建边的哈希值字典
|
# 创建边的哈希值字典
|
||||||
|
|
@ -445,12 +444,12 @@ class Hippocampus:
|
||||||
'num': 1,
|
'num': 1,
|
||||||
'hash': edge_hash
|
'hash': edge_hash
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
else:
|
else:
|
||||||
# 检查边的特征值是否变化
|
# 检查边的特征值是否变化
|
||||||
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
||||||
logger.info(f"更新边: {source} - {target}")
|
logger.info(f"更新边: {source} - {target}")
|
||||||
self.memory_graph.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {'hash': edge_hash}}
|
{'$set': {'hash': edge_hash}}
|
||||||
)
|
)
|
||||||
|
|
@ -461,7 +460,7 @@ class Hippocampus:
|
||||||
if edge_key not in memory_edge_set:
|
if edge_key not in memory_edge_set:
|
||||||
source, target = edge_key
|
source, target = edge_key
|
||||||
logger.info(f"删除多余边: {source} - {target}")
|
logger.info(f"删除多余边: {source} - {target}")
|
||||||
self.memory_graph.db.graph_data.edges.delete_one({
|
db.graph_data.edges.delete_one({
|
||||||
'source': source,
|
'source': source,
|
||||||
'target': target
|
'target': target
|
||||||
})
|
})
|
||||||
|
|
@ -487,9 +486,9 @@ class Hippocampus:
|
||||||
topic: 要删除的节点概念
|
topic: 要删除的节点概念
|
||||||
"""
|
"""
|
||||||
# 删除节点
|
# 删除节点
|
||||||
self.memory_graph.db.graph_data.nodes.delete_one({'concept': topic})
|
db.graph_data.nodes.delete_one({'concept': topic})
|
||||||
# 删除所有涉及该节点的边
|
# 删除所有涉及该节点的边
|
||||||
self.memory_graph.db.graph_data.edges.delete_many({
|
db.graph_data.edges.delete_many({
|
||||||
'$or': [
|
'$or': [
|
||||||
{'source': topic},
|
{'source': topic},
|
||||||
{'target': topic}
|
{'target': topic}
|
||||||
|
|
@ -902,17 +901,6 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
||||||
plt.show()
|
plt.show()
|
||||||
|
|
||||||
async def main():
|
async def main():
|
||||||
# 初始化数据库
|
|
||||||
logger.info("正在初始化数据库连接...")
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
|
|
||||||
test_pare = {'do_build_memory':False,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
test_pare = {'do_build_memory':False,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
||||||
|
|
|
||||||
|
|
@ -38,7 +38,7 @@ import jieba
|
||||||
|
|
||||||
# from chat.config import global_config
|
# from chat.config import global_config
|
||||||
sys.path.append("C:/GitHub/MaiMBot") # 添加项目根目录到 Python 路径
|
sys.path.append("C:/GitHub/MaiMBot") # 添加项目根目录到 Python 路径
|
||||||
from src.common.database import Database
|
from src.common.database import db
|
||||||
from src.plugins.memory_system.offline_llm import LLMModel
|
from src.plugins.memory_system.offline_llm import LLMModel
|
||||||
|
|
||||||
# 获取当前文件的目录
|
# 获取当前文件的目录
|
||||||
|
|
@ -56,45 +56,6 @@ else:
|
||||||
logger.warning(f"未找到环境变量文件: {env_path}")
|
logger.warning(f"未找到环境变量文件: {env_path}")
|
||||||
logger.info("将使用默认配置")
|
logger.info("将使用默认配置")
|
||||||
|
|
||||||
class Database:
|
|
||||||
_instance = None
|
|
||||||
db = None
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def get_instance(cls):
|
|
||||||
if cls._instance is None:
|
|
||||||
cls._instance = cls()
|
|
||||||
return cls._instance
|
|
||||||
|
|
||||||
def __init__(self):
|
|
||||||
if not Database.db:
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
|
|
||||||
@classmethod
|
|
||||||
def initialize(cls, host, port, db_name, username=None, password=None, auth_source="admin"):
|
|
||||||
try:
|
|
||||||
if username and password:
|
|
||||||
uri = f"mongodb://{username}:{password}@{host}:{port}/{db_name}?authSource={auth_source}"
|
|
||||||
else:
|
|
||||||
uri = f"mongodb://{host}:{port}"
|
|
||||||
|
|
||||||
client = pymongo.MongoClient(uri)
|
|
||||||
cls.db = client[db_name]
|
|
||||||
# 测试连接
|
|
||||||
client.server_info()
|
|
||||||
logger.success("MongoDB连接成功!")
|
|
||||||
|
|
||||||
except Exception as e:
|
|
||||||
logger.error(f"初始化MongoDB失败: {str(e)}")
|
|
||||||
raise
|
|
||||||
|
|
||||||
def calculate_information_content(text):
|
def calculate_information_content(text):
|
||||||
"""计算文本的信息量(熵)"""
|
"""计算文本的信息量(熵)"""
|
||||||
|
|
@ -108,7 +69,7 @@ def calculate_information_content(text):
|
||||||
|
|
||||||
return entropy
|
return entropy
|
||||||
|
|
||||||
def get_cloest_chat_from_db(db, length: int, timestamp: str):
|
def get_closest_chat_from_db(length: int, timestamp: str):
|
||||||
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
"""从数据库中获取最接近指定时间戳的聊天记录,并记录读取次数
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
|
|
@ -163,7 +124,7 @@ class Memory_cortex:
|
||||||
default_time = datetime.datetime.now().timestamp()
|
default_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
# 从数据库加载所有节点
|
# 从数据库加载所有节点
|
||||||
nodes = self.memory_graph.db.graph_data.nodes.find()
|
nodes = db.graph_data.nodes.find()
|
||||||
for node in nodes:
|
for node in nodes:
|
||||||
concept = node['concept']
|
concept = node['concept']
|
||||||
memory_items = node.get('memory_items', [])
|
memory_items = node.get('memory_items', [])
|
||||||
|
|
@ -180,7 +141,7 @@ class Memory_cortex:
|
||||||
created_time = default_time
|
created_time = default_time
|
||||||
last_modified = default_time
|
last_modified = default_time
|
||||||
# 更新数据库中的节点
|
# 更新数据库中的节点
|
||||||
self.memory_graph.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'created_time': created_time,
|
'created_time': created_time,
|
||||||
|
|
@ -196,7 +157,7 @@ class Memory_cortex:
|
||||||
last_modified=last_modified)
|
last_modified=last_modified)
|
||||||
|
|
||||||
# 从数据库加载所有边
|
# 从数据库加载所有边
|
||||||
edges = self.memory_graph.db.graph_data.edges.find()
|
edges = db.graph_data.edges.find()
|
||||||
for edge in edges:
|
for edge in edges:
|
||||||
source = edge['source']
|
source = edge['source']
|
||||||
target = edge['target']
|
target = edge['target']
|
||||||
|
|
@ -212,7 +173,7 @@ class Memory_cortex:
|
||||||
created_time = default_time
|
created_time = default_time
|
||||||
last_modified = default_time
|
last_modified = default_time
|
||||||
# 更新数据库中的边
|
# 更新数据库中的边
|
||||||
self.memory_graph.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'created_time': created_time,
|
'created_time': created_time,
|
||||||
|
|
@ -256,7 +217,7 @@ class Memory_cortex:
|
||||||
current_time = datetime.datetime.now().timestamp()
|
current_time = datetime.datetime.now().timestamp()
|
||||||
|
|
||||||
# 获取数据库中所有节点和内存中所有节点
|
# 获取数据库中所有节点和内存中所有节点
|
||||||
db_nodes = list(self.memory_graph.db.graph_data.nodes.find())
|
db_nodes = list(db.graph_data.nodes.find())
|
||||||
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
memory_nodes = list(self.memory_graph.G.nodes(data=True))
|
||||||
|
|
||||||
# 转换数据库节点为字典格式,方便查找
|
# 转换数据库节点为字典格式,方便查找
|
||||||
|
|
@ -280,7 +241,7 @@ class Memory_cortex:
|
||||||
'created_time': data.get('created_time', current_time),
|
'created_time': data.get('created_time', current_time),
|
||||||
'last_modified': data.get('last_modified', current_time)
|
'last_modified': data.get('last_modified', current_time)
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.nodes.insert_one(node_data)
|
db.graph_data.nodes.insert_one(node_data)
|
||||||
else:
|
else:
|
||||||
# 获取数据库中节点的特征值
|
# 获取数据库中节点的特征值
|
||||||
db_node = db_nodes_dict[concept]
|
db_node = db_nodes_dict[concept]
|
||||||
|
|
@ -288,7 +249,7 @@ class Memory_cortex:
|
||||||
|
|
||||||
# 如果特征值不同,则更新节点
|
# 如果特征值不同,则更新节点
|
||||||
if db_hash != memory_hash:
|
if db_hash != memory_hash:
|
||||||
self.memory_graph.db.graph_data.nodes.update_one(
|
db.graph_data.nodes.update_one(
|
||||||
{'concept': concept},
|
{'concept': concept},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'memory_items': memory_items,
|
'memory_items': memory_items,
|
||||||
|
|
@ -301,10 +262,10 @@ class Memory_cortex:
|
||||||
memory_concepts = set(node[0] for node in memory_nodes)
|
memory_concepts = set(node[0] for node in memory_nodes)
|
||||||
for db_node in db_nodes:
|
for db_node in db_nodes:
|
||||||
if db_node['concept'] not in memory_concepts:
|
if db_node['concept'] not in memory_concepts:
|
||||||
self.memory_graph.db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
db.graph_data.nodes.delete_one({'concept': db_node['concept']})
|
||||||
|
|
||||||
# 处理边的信息
|
# 处理边的信息
|
||||||
db_edges = list(self.memory_graph.db.graph_data.edges.find())
|
db_edges = list(db.graph_data.edges.find())
|
||||||
memory_edges = list(self.memory_graph.G.edges(data=True))
|
memory_edges = list(self.memory_graph.G.edges(data=True))
|
||||||
|
|
||||||
# 创建边的哈希值字典
|
# 创建边的哈希值字典
|
||||||
|
|
@ -332,11 +293,11 @@ class Memory_cortex:
|
||||||
'created_time': data.get('created_time', current_time),
|
'created_time': data.get('created_time', current_time),
|
||||||
'last_modified': data.get('last_modified', current_time)
|
'last_modified': data.get('last_modified', current_time)
|
||||||
}
|
}
|
||||||
self.memory_graph.db.graph_data.edges.insert_one(edge_data)
|
db.graph_data.edges.insert_one(edge_data)
|
||||||
else:
|
else:
|
||||||
# 检查边的特征值是否变化
|
# 检查边的特征值是否变化
|
||||||
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
if db_edge_dict[edge_key]['hash'] != edge_hash:
|
||||||
self.memory_graph.db.graph_data.edges.update_one(
|
db.graph_data.edges.update_one(
|
||||||
{'source': source, 'target': target},
|
{'source': source, 'target': target},
|
||||||
{'$set': {
|
{'$set': {
|
||||||
'hash': edge_hash,
|
'hash': edge_hash,
|
||||||
|
|
@ -350,7 +311,7 @@ class Memory_cortex:
|
||||||
for edge_key in db_edge_dict:
|
for edge_key in db_edge_dict:
|
||||||
if edge_key not in memory_edge_set:
|
if edge_key not in memory_edge_set:
|
||||||
source, target = edge_key
|
source, target = edge_key
|
||||||
self.memory_graph.db.graph_data.edges.delete_one({
|
db.graph_data.edges.delete_one({
|
||||||
'source': source,
|
'source': source,
|
||||||
'target': target
|
'target': target
|
||||||
})
|
})
|
||||||
|
|
@ -365,9 +326,9 @@ class Memory_cortex:
|
||||||
topic: 要删除的节点概念
|
topic: 要删除的节点概念
|
||||||
"""
|
"""
|
||||||
# 删除节点
|
# 删除节点
|
||||||
self.memory_graph.db.graph_data.nodes.delete_one({'concept': topic})
|
db.graph_data.nodes.delete_one({'concept': topic})
|
||||||
# 删除所有涉及该节点的边
|
# 删除所有涉及该节点的边
|
||||||
self.memory_graph.db.graph_data.edges.delete_many({
|
db.graph_data.edges.delete_many({
|
||||||
'$or': [
|
'$or': [
|
||||||
{'source': topic},
|
{'source': topic},
|
||||||
{'target': topic}
|
{'target': topic}
|
||||||
|
|
@ -377,7 +338,6 @@ class Memory_cortex:
|
||||||
class Memory_graph:
|
class Memory_graph:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.G = nx.Graph() # 使用 networkx 的图结构
|
self.G = nx.Graph() # 使用 networkx 的图结构
|
||||||
self.db = Database.get_instance()
|
|
||||||
|
|
||||||
def connect_dot(self, concept1, concept2):
|
def connect_dot(self, concept1, concept2):
|
||||||
# 避免自连接
|
# 避免自连接
|
||||||
|
|
@ -492,19 +452,19 @@ class Hippocampus:
|
||||||
# 短期:1h 中期:4h 长期:24h
|
# 短期:1h 中期:4h 长期:24h
|
||||||
for _ in range(time_frequency.get('near')):
|
for _ in range(time_frequency.get('near')):
|
||||||
random_time = current_timestamp - random.randint(1, 3600*4)
|
random_time = current_timestamp - random.randint(1, 3600*4)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('mid')):
|
for _ in range(time_frequency.get('mid')):
|
||||||
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
random_time = current_timestamp - random.randint(3600*4, 3600*24)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
for _ in range(time_frequency.get('far')):
|
for _ in range(time_frequency.get('far')):
|
||||||
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
random_time = current_timestamp - random.randint(3600*24, 3600*24*7)
|
||||||
messages = get_cloest_chat_from_db(db=self.memory_graph.db, length=chat_size, timestamp=random_time)
|
messages = get_closest_chat_from_db(length=chat_size, timestamp=random_time)
|
||||||
if messages:
|
if messages:
|
||||||
chat_samples.append(messages)
|
chat_samples.append(messages)
|
||||||
|
|
||||||
|
|
@ -1134,7 +1094,6 @@ def visualize_graph_lite(memory_graph: Memory_graph, color_by_memory: bool = Fal
|
||||||
async def main():
|
async def main():
|
||||||
# 初始化数据库
|
# 初始化数据库
|
||||||
logger.info("正在初始化数据库连接...")
|
logger.info("正在初始化数据库连接...")
|
||||||
db = Database.get_instance()
|
|
||||||
start_time = time.time()
|
start_time = time.time()
|
||||||
|
|
||||||
test_pare = {'do_build_memory':True,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
test_pare = {'do_build_memory':True,'do_forget_topic':False,'do_visualize_graph':True,'do_query':False,'do_merge_memory':False}
|
||||||
|
|
|
||||||
|
|
@ -10,7 +10,7 @@ from nonebot import get_driver
|
||||||
import base64
|
import base64
|
||||||
from PIL import Image
|
from PIL import Image
|
||||||
import io
|
import io
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
from ..chat.config import global_config
|
from ..chat.config import global_config
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
|
|
@ -34,17 +34,16 @@ class LLM_request:
|
||||||
self.pri_out = model.get("pri_out", 0)
|
self.pri_out = model.get("pri_out", 0)
|
||||||
|
|
||||||
# 获取数据库实例
|
# 获取数据库实例
|
||||||
self.db = Database.get_instance()
|
|
||||||
self._init_database()
|
self._init_database()
|
||||||
|
|
||||||
def _init_database(self):
|
def _init_database(self):
|
||||||
"""初始化数据库集合"""
|
"""初始化数据库集合"""
|
||||||
try:
|
try:
|
||||||
# 创建llm_usage集合的索引
|
# 创建llm_usage集合的索引
|
||||||
self.db.llm_usage.create_index([("timestamp", 1)])
|
db.llm_usage.create_index([("timestamp", 1)])
|
||||||
self.db.llm_usage.create_index([("model_name", 1)])
|
db.llm_usage.create_index([("model_name", 1)])
|
||||||
self.db.llm_usage.create_index([("user_id", 1)])
|
db.llm_usage.create_index([("user_id", 1)])
|
||||||
self.db.llm_usage.create_index([("request_type", 1)])
|
db.llm_usage.create_index([("request_type", 1)])
|
||||||
except Exception:
|
except Exception:
|
||||||
logger.error("创建数据库索引失败")
|
logger.error("创建数据库索引失败")
|
||||||
|
|
||||||
|
|
@ -73,7 +72,7 @@ class LLM_request:
|
||||||
"status": "success",
|
"status": "success",
|
||||||
"timestamp": datetime.now()
|
"timestamp": datetime.now()
|
||||||
}
|
}
|
||||||
self.db.llm_usage.insert_one(usage_data)
|
db.llm_usage.insert_one(usage_data)
|
||||||
logger.info(
|
logger.info(
|
||||||
f"Token使用情况 - 模型: {self.model_name}, "
|
f"Token使用情况 - 模型: {self.model_name}, "
|
||||||
f"用户: {user_id}, 类型: {request_type}, "
|
f"用户: {user_id}, 类型: {request_type}, "
|
||||||
|
|
@ -133,7 +132,7 @@ class LLM_request:
|
||||||
# 常见Error Code Mapping
|
# 常见Error Code Mapping
|
||||||
error_code_mapping = {
|
error_code_mapping = {
|
||||||
400: "参数不正确",
|
400: "参数不正确",
|
||||||
401: "API key 错误,认证失败",
|
401: "API key 错误,认证失败,请检查/config/bot_config.toml和.env.prod中的配置是否正确哦~",
|
||||||
402: "账号余额不足",
|
402: "账号余额不足",
|
||||||
403: "需要实名,或余额不足",
|
403: "需要实名,或余额不足",
|
||||||
404: "Not Found",
|
404: "Not Found",
|
||||||
|
|
|
||||||
|
|
@ -8,18 +8,20 @@ from nonebot import get_driver
|
||||||
|
|
||||||
from src.plugins.chat.config import global_config
|
from src.plugins.chat.config import global_config
|
||||||
|
|
||||||
from ...common.database import Database # 使用正确的导入语法
|
from ...common.database import db # 使用正确的导入语法
|
||||||
from ..models.utils_model import LLM_request
|
from ..models.utils_model import LLM_request
|
||||||
|
|
||||||
driver = get_driver()
|
driver = get_driver()
|
||||||
config = driver.config
|
config = driver.config
|
||||||
|
|
||||||
|
|
||||||
class ScheduleGenerator:
|
class ScheduleGenerator:
|
||||||
|
enable_output: bool = True
|
||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
# 根据global_config.llm_normal这一字典配置指定模型
|
# 根据global_config.llm_normal这一字典配置指定模型
|
||||||
# self.llm_scheduler = LLMModel(model = global_config.llm_normal,temperature=0.9)
|
# self.llm_scheduler = LLMModel(model = global_config.llm_normal,temperature=0.9)
|
||||||
self.llm_scheduler = LLM_request(model=global_config.llm_normal, temperature=0.9)
|
self.llm_scheduler = LLM_request(model=global_config.llm_normal, temperature=0.9)
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.today_schedule_text = ""
|
self.today_schedule_text = ""
|
||||||
self.today_schedule = {}
|
self.today_schedule = {}
|
||||||
self.tomorrow_schedule_text = ""
|
self.tomorrow_schedule_text = ""
|
||||||
|
|
@ -33,43 +35,50 @@ class ScheduleGenerator:
|
||||||
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
|
yesterday = datetime.datetime.now() - datetime.timedelta(days=1)
|
||||||
|
|
||||||
self.today_schedule_text, self.today_schedule = await self.generate_daily_schedule(target_date=today)
|
self.today_schedule_text, self.today_schedule = await self.generate_daily_schedule(target_date=today)
|
||||||
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(target_date=tomorrow,
|
self.tomorrow_schedule_text, self.tomorrow_schedule = await self.generate_daily_schedule(
|
||||||
read_only=True)
|
target_date=tomorrow, read_only=True
|
||||||
|
)
|
||||||
self.yesterday_schedule_text, self.yesterday_schedule = await self.generate_daily_schedule(
|
self.yesterday_schedule_text, self.yesterday_schedule = await self.generate_daily_schedule(
|
||||||
target_date=yesterday, read_only=True)
|
target_date=yesterday, read_only=True
|
||||||
|
)
|
||||||
async def generate_daily_schedule(self, target_date: datetime.datetime = None, read_only: bool = False) -> Dict[
|
|
||||||
str, str]:
|
|
||||||
|
|
||||||
|
async def generate_daily_schedule(
|
||||||
|
self, target_date: datetime.datetime = None, read_only: bool = False
|
||||||
|
) -> Dict[str, str]:
|
||||||
date_str = target_date.strftime("%Y-%m-%d")
|
date_str = target_date.strftime("%Y-%m-%d")
|
||||||
weekday = target_date.strftime("%A")
|
weekday = target_date.strftime("%A")
|
||||||
|
|
||||||
schedule_text = str
|
schedule_text = str
|
||||||
|
|
||||||
existing_schedule = self.db.schedule.find_one({"date": date_str})
|
existing_schedule = db.schedule.find_one({"date": date_str})
|
||||||
if existing_schedule:
|
if existing_schedule:
|
||||||
logger.debug(f"{date_str}的日程已存在:")
|
if self.enable_output:
|
||||||
|
logger.debug(f"{date_str}的日程已存在:")
|
||||||
schedule_text = existing_schedule["schedule"]
|
schedule_text = existing_schedule["schedule"]
|
||||||
# print(self.schedule_text)
|
# print(self.schedule_text)
|
||||||
|
|
||||||
elif not read_only:
|
elif not read_only:
|
||||||
logger.debug(f"{date_str}的日程不存在,准备生成新的日程。")
|
logger.debug(f"{date_str}的日程不存在,准备生成新的日程。")
|
||||||
prompt = f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:""" + \
|
prompt = (
|
||||||
"""
|
f"""我是{global_config.BOT_NICKNAME},{global_config.PROMPT_SCHEDULE_GEN},请为我生成{date_str}({weekday})的日程安排,包括:"""
|
||||||
|
+ """
|
||||||
1. 早上的学习和工作安排
|
1. 早上的学习和工作安排
|
||||||
2. 下午的活动和任务
|
2. 下午的活动和任务
|
||||||
3. 晚上的计划和休息时间
|
3. 晚上的计划和休息时间
|
||||||
请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
|
请按照时间顺序列出具体时间点和对应的活动,用一个时间点而不是时间段来表示时间,用JSON格式返回日程表,仅返回内容,不要返回注释,不要添加任何markdown或代码块样式,时间采用24小时制,格式为{"时间": "活动","时间": "活动",...}。"""
|
||||||
|
)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
schedule_text, _ = await self.llm_scheduler.generate_response(prompt)
|
schedule_text, _ = await self.llm_scheduler.generate_response(prompt)
|
||||||
self.db.schedule.insert_one({"date": date_str, "schedule": schedule_text})
|
db.schedule.insert_one({"date": date_str, "schedule": schedule_text})
|
||||||
|
self.enable_output = True
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logger.error(f"生成日程失败: {str(e)}")
|
logger.error(f"生成日程失败: {str(e)}")
|
||||||
schedule_text = "生成日程时出错了"
|
schedule_text = "生成日程时出错了"
|
||||||
# print(self.schedule_text)
|
# print(self.schedule_text)
|
||||||
else:
|
else:
|
||||||
logger.debug(f"{date_str}的日程不存在。")
|
if self.enable_output:
|
||||||
|
logger.debug(f"{date_str}的日程不存在。")
|
||||||
schedule_text = "忘了"
|
schedule_text = "忘了"
|
||||||
|
|
||||||
return schedule_text, None
|
return schedule_text, None
|
||||||
|
|
@ -96,7 +105,7 @@ class ScheduleGenerator:
|
||||||
|
|
||||||
# 找到最接近当前时间的任务
|
# 找到最接近当前时间的任务
|
||||||
closest_time = None
|
closest_time = None
|
||||||
min_diff = float('inf')
|
min_diff = float("inf")
|
||||||
|
|
||||||
# 检查今天的日程
|
# 检查今天的日程
|
||||||
if not self.today_schedule:
|
if not self.today_schedule:
|
||||||
|
|
@ -143,12 +152,13 @@ class ScheduleGenerator:
|
||||||
"""打印完整的日程安排"""
|
"""打印完整的日程安排"""
|
||||||
if not self._parse_schedule(self.today_schedule_text):
|
if not self._parse_schedule(self.today_schedule_text):
|
||||||
logger.warning("今日日程有误,将在下次运行时重新生成")
|
logger.warning("今日日程有误,将在下次运行时重新生成")
|
||||||
self.db.schedule.delete_one({"date": datetime.datetime.now().strftime("%Y-%m-%d")})
|
db.schedule.delete_one({"date": datetime.datetime.now().strftime("%Y-%m-%d")})
|
||||||
else:
|
else:
|
||||||
logger.info("=== 今日日程安排 ===")
|
logger.info("=== 今日日程安排 ===")
|
||||||
for time_str, activity in self.today_schedule.items():
|
for time_str, activity in self.today_schedule.items():
|
||||||
logger.info(f"时间[{time_str}]: 活动[{activity}]")
|
logger.info(f"时间[{time_str}]: 活动[{activity}]")
|
||||||
logger.info("==================")
|
logger.info("==================")
|
||||||
|
self.enable_output = False
|
||||||
|
|
||||||
|
|
||||||
# def main():
|
# def main():
|
||||||
|
|
|
||||||
|
|
@ -5,7 +5,7 @@ from datetime import datetime, timedelta
|
||||||
from typing import Any, Dict
|
from typing import Any, Dict
|
||||||
from loguru import logger
|
from loguru import logger
|
||||||
|
|
||||||
from ...common.database import Database
|
from ...common.database import db
|
||||||
|
|
||||||
|
|
||||||
class LLMStatistics:
|
class LLMStatistics:
|
||||||
|
|
@ -15,7 +15,6 @@ class LLMStatistics:
|
||||||
Args:
|
Args:
|
||||||
output_file: 统计结果输出文件路径
|
output_file: 统计结果输出文件路径
|
||||||
"""
|
"""
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.output_file = output_file
|
self.output_file = output_file
|
||||||
self.running = False
|
self.running = False
|
||||||
self.stats_thread = None
|
self.stats_thread = None
|
||||||
|
|
@ -53,7 +52,7 @@ class LLMStatistics:
|
||||||
"costs_by_model": defaultdict(float)
|
"costs_by_model": defaultdict(float)
|
||||||
}
|
}
|
||||||
|
|
||||||
cursor = self.db.llm_usage.find({
|
cursor = db.llm_usage.find({
|
||||||
"timestamp": {"$gte": start_time}
|
"timestamp": {"$gte": start_time}
|
||||||
})
|
})
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -14,7 +14,7 @@ root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
|
||||||
sys.path.append(root_path)
|
sys.path.append(root_path)
|
||||||
|
|
||||||
# 现在可以导入src模块
|
# 现在可以导入src模块
|
||||||
from src.common.database import Database
|
from src.common.database import db
|
||||||
|
|
||||||
# 加载根目录下的env.edv文件
|
# 加载根目录下的env.edv文件
|
||||||
env_path = os.path.join(root_path, ".env.prod")
|
env_path = os.path.join(root_path, ".env.prod")
|
||||||
|
|
@ -24,18 +24,6 @@ load_dotenv(env_path)
|
||||||
|
|
||||||
class KnowledgeLibrary:
|
class KnowledgeLibrary:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
# 初始化数据库连接
|
|
||||||
if Database._instance is None:
|
|
||||||
Database.initialize(
|
|
||||||
uri=os.getenv("MONGODB_URI"),
|
|
||||||
host=os.getenv("MONGODB_HOST", "127.0.0.1"),
|
|
||||||
port=int(os.getenv("MONGODB_PORT", "27017")),
|
|
||||||
db_name=os.getenv("DATABASE_NAME", "MegBot"),
|
|
||||||
username=os.getenv("MONGODB_USERNAME"),
|
|
||||||
password=os.getenv("MONGODB_PASSWORD"),
|
|
||||||
auth_source=os.getenv("MONGODB_AUTH_SOURCE"),
|
|
||||||
)
|
|
||||||
self.db = Database.get_instance()
|
|
||||||
self.raw_info_dir = "data/raw_info"
|
self.raw_info_dir = "data/raw_info"
|
||||||
self._ensure_dirs()
|
self._ensure_dirs()
|
||||||
self.api_key = os.getenv("SILICONFLOW_KEY")
|
self.api_key = os.getenv("SILICONFLOW_KEY")
|
||||||
|
|
@ -176,7 +164,7 @@ class KnowledgeLibrary:
|
||||||
|
|
||||||
try:
|
try:
|
||||||
current_hash = self.calculate_file_hash(file_path)
|
current_hash = self.calculate_file_hash(file_path)
|
||||||
processed_record = self.db.processed_files.find_one({"file_path": file_path})
|
processed_record = db.processed_files.find_one({"file_path": file_path})
|
||||||
|
|
||||||
if processed_record:
|
if processed_record:
|
||||||
if processed_record.get("hash") == current_hash:
|
if processed_record.get("hash") == current_hash:
|
||||||
|
|
@ -197,14 +185,14 @@ class KnowledgeLibrary:
|
||||||
"split_length": knowledge_length,
|
"split_length": knowledge_length,
|
||||||
"created_at": datetime.now()
|
"created_at": datetime.now()
|
||||||
}
|
}
|
||||||
self.db.knowledges.insert_one(knowledge)
|
db.knowledges.insert_one(knowledge)
|
||||||
result["chunks_processed"] += 1
|
result["chunks_processed"] += 1
|
||||||
|
|
||||||
split_by = processed_record.get("split_by", []) if processed_record else []
|
split_by = processed_record.get("split_by", []) if processed_record else []
|
||||||
if knowledge_length not in split_by:
|
if knowledge_length not in split_by:
|
||||||
split_by.append(knowledge_length)
|
split_by.append(knowledge_length)
|
||||||
|
|
||||||
self.db.knowledges.processed_files.update_one(
|
db.knowledges.processed_files.update_one(
|
||||||
{"file_path": file_path},
|
{"file_path": file_path},
|
||||||
{
|
{
|
||||||
"$set": {
|
"$set": {
|
||||||
|
|
@ -322,7 +310,7 @@ class KnowledgeLibrary:
|
||||||
{"$project": {"content": 1, "similarity": 1, "file_path": 1}}
|
{"$project": {"content": 1, "similarity": 1, "file_path": 1}}
|
||||||
]
|
]
|
||||||
|
|
||||||
results = list(self.db.knowledges.aggregate(pipeline))
|
results = list(db.knowledges.aggregate(pipeline))
|
||||||
return results
|
return results
|
||||||
|
|
||||||
# 创建单例实例
|
# 创建单例实例
|
||||||
|
|
@ -346,7 +334,7 @@ if __name__ == "__main__":
|
||||||
elif choice == '2':
|
elif choice == '2':
|
||||||
confirm = input("确定要删除所有知识吗?这个操作不可撤销!(y/n): ").strip().lower()
|
confirm = input("确定要删除所有知识吗?这个操作不可撤销!(y/n): ").strip().lower()
|
||||||
if confirm == 'y':
|
if confirm == 'y':
|
||||||
knowledge_library.db.knowledges.delete_many({})
|
db.knowledges.delete_many({})
|
||||||
console.print("[green]已清空所有知识![/green]")
|
console.print("[green]已清空所有知识![/green]")
|
||||||
continue
|
continue
|
||||||
elif choice == '1':
|
elif choice == '1':
|
||||||
|
|
|
||||||
|
|
@ -23,7 +23,7 @@ CHAT_ANY_WHERE_BASE_URL=https://api.chatanywhere.tech/v1
|
||||||
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/
|
SILICONFLOW_BASE_URL=https://api.siliconflow.cn/v1/
|
||||||
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1
|
DEEP_SEEK_BASE_URL=https://api.deepseek.com/v1
|
||||||
|
|
||||||
#定义你要用的api的base_url
|
#定义你要用的api的key(需要去对应网站申请哦)
|
||||||
DEEP_SEEK_KEY=
|
DEEP_SEEK_KEY=
|
||||||
CHAT_ANY_WHERE_KEY=
|
CHAT_ANY_WHERE_KEY=
|
||||||
SILICONFLOW_KEY=
|
SILICONFLOW_KEY=
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue